[bws_captcha]Cet article est la suite de :
« E2E Network Slicing : le découpage du réseau de bout en bout (Partie 1)
III) La virtualisation du cœur de réseau
Les entités du cœur de réseau AMF, SMF, NEF, PCF sont des fonctions qui peuvent être virtualisées. Ces fonctions gèrent le plan de contrôle du réseau de mobiles et les performances fonctionnelles sont analysées au niveau du support opérationnel OSS (FCAPS).
L’entité UPF peut également être virtualisée, cette fonction gère le plan utilisateur. La fonction UPF possède des capacités d’aiguillage de trafic à partir de la classification de flux UL-CL (Uplink Classifier). Ainsi, la fonction UPF peut avoir le rôle de point de branchement (multi-homing), point d’ancrage de session (PSA : PDU Session Anchor) ou classificateur de flux pour définir le prochain saut. La classification de flux est une fonctionnalité supportée par la fonction UPF afin de diriger le trafic localement en fonction des filtres appliqués au trafic UE.
Le contrôle des fonctions virtuelles dans le cœur de réseau 5G est réalisé par deux fonctions nommées NSSF (Network Slice Selection Function) et NRF (Network Repository Function).
- Le rôle du NSSF est de sélectionner le jeu de tranches réseau que l’utilisateur va pouvoir utiliser en fonction de son contrat d’abonnement (SLA) pour lui apporter la QoE (Quality of Experience) souhaitée. Le choix du slice se faisant au moment de l’enregistrement du mobile, la fonction NSSF dialogue avec la fonction AMF ou la fonction NSSF d’un autre PLMN.
- Le rôle du NRF est de fournir un contrôle des fonctions virtuelles (NF) et des services proposés par les fonctions virtuelles.
- La fonction NRF est un catalogue qui est mis à jour au moment de l’activation de la fonction virtuelle (enregistrement) et mis à jour lorsque la fonction virtuelle est redimensionnée. Elle propose ainsi un service de découverte de fonctions virtuelles
- Toute fonction virtuelle NF peut demander à la fonction NRF, par une procédure de souscription, d’être informée dès qu’une nouvelle instance est créée.

Figure 5 : Inscription d’une fonction virtuelle au niveau de la fonction NRF (TS 29.510)
Une sous-instance virtuelle est composée au minimum de fonctions AMF, SMF, PCF, NRF. L’opérateur (OSS) met en place un ou plusieurs sous réseaux virtuels SNI et peut à tout moment activer ou désactiver un sous-réseau (procédure NSI figure 3). Chaque fonction activée vient se déclarer auprès de la fonction NRF (figure 5).
Une instance de réseau permet de gérer un type de service. Le type de service est défini par la variable S-NSSAI. Le S-NSSAI contient 2 champs :
- SST sur 8 bits défini le type de slice (Slice Service Type)
- SST = 1 : eMBB (normalisée 3GPP) ;
- SST = 2 : URLLC (normalisée 3GPP) ;
- SST = 3 : mMTC (normalisée 3GPP) ;
- SST = 4 : V2X (normalisée 3GPP) ;
- SST= 5 : HMTC (High Performance MTC normalisée 3GPP – R.17 – mise à jour janvier 2022);
- SST=6 : HDLLC (High Data Low Latency Communication 3GPP – R.18 mise à jour juin 2023)
- SST de 128 à 255 sont définis par l’opérateur.
- SD (Slice Differentiator) est une information optionnelle qui permet de décliner plusieurs types de sous-service dans une catégorie SST donnée afin de différencier les clients.
La fonction NSSF permet d’identifier les NSI. Cette fonction est configurable via une API REST.
Voici un exemple de configuration de la fonction NSSF :
https://host:port/v1/nssf/configurations/nsiprofiles
POST
Content-Type: application/json
BODY
{
« name »: « NSI001 »,
« nrfUri »: « https://nrf.bloglaunay.com »,
« nsiId »: « 1 »,
« targetAmfSets »:
[
{
« regionId »: « 01 »,
« setId »: « 001 »,
« setFqdn »: « set001.region01.amfset.5gc.mnc111.mcc208.3gppnetwork.org »
},
{
« regionId »: « 01 »,
« setId »: « 002 »,
« setFqdn »: « set002.region01.amfset.5gc.mnc111.mcc208.3gppnetwork.org »
}
]
}
Pour être plus complet, la configuration de la fonction NSSF permet aussi de diriger le choix de la fonction NRF en fonction du NSSAI demandé.
D’un point de vue opérateur : Lorsqu’une tranche de réseau est mise en œuvre, la fonction AMF peut toujours mettre à jour la configuration S-NSSAI de la fonction NSSF afin d’informer celle-ci des types de service supportés par la fonction AMF sur une zone de localisation TA.
Une fonction AMF peut gérer plusieurs tranches de réseaux S-NSSAI (il n’y a pas de limite fixée au niveau du cœur de réseau).

Figure 6 : La mise à jour de la fonction NSSF
L’entité NSSF sélectionne le (ou les) instances de réseau NSI correspondant(s) à la demande du mobile à partir du (ou de la liste des) S-NSSAI et détermine ainsi les fonctions AMF candidates correspondant spécifiquement (ou au mieux) à la demande de l’UE. Eventuellement, l’entité NSSF interroge la base de données NRF (Network Repository Function).

Figure 7 : Procédure d’enregistrement et sélection du NSI
L’entité NSSF renvoie à la fonction AMF qui l’a interrogée, la valeur NSSAI autorisée sur la zone TA et la liste des fonctions AMF candidates (figure 7).
Lorsque la station de base s’active (mise en route ou suite à une procédure de ré-initialisation), elle interroge les fonctions AMF pour connaître les tranches de réseaux (slices) supportées par chaque fonction AMF accessible comme le montre la figure 8.

Figure 8 : La déclaration des slices supportées par les fonctions AMF auprès de l’entité gNB
Si la station de base gNB était déjà en fonctionnement, alors elle est informée des modifications NSSAI apportées au niveau de la fonction AMF via le message NG Setup request (figure 9).

Figure 9 : La mise à jour des slices supportées par les fonctions AMF auprès de l’entité gNB
Lorsque le mobile s’active, il réalise une procédure d’attachement auprès d’une fonction AMF. L’attachement se fait sur une fonction AMF parmi toutes les fonctions AMF qui ont été activées par le support opérationnel OSS et accessible par la station de base gNB.
La sélection de l’entité AMF est réalisée au moment de la procédure d’attachement. Le choix est effectué à partir de l’identifiant NSSAI émis dans la requête NAS REGISTER. La station de base gNB reçoit la requête RRC qui porte le message NAS et l’indicateur NSSAI à partir duquel il sélectionne une fonction AMF. Si plusieurs fonctions AMF candidates peuvent être choisies (cf figure 8), la station de base gNB fait son choix par équilibrage de charge.
La fonction AMF sélectionnée par l’entité gNB interroge la base de données UDM pour vérifier que l’indicateur NSSAI demandé par le terminal (requested NSSAI) est accepté. L’entité UDM transmet à la fonction AMF le NSSAI autorisé pour ce client (allowed NSSAI). A partir de ce moment, la fonction AMF consulte la fonction NSSF (Network Slicing Selection Function) à partir d’une requête GET en indiquant la liste des S-NSSAI autorisés.
Si après consultation de la fonction NSSF, la fonction AMF sélectionnée initialement (appelée AMF source) par la station de base n’est pas appropriée pour les services demandés (NSSAI), alors la fonction AMF source réalise la procédure de ré-allocation de la fonction AMF.
Concernant la ré-allocation (lors de la procédure d’attachement), deux options sont possibles :
Dans le cas de l’option A (figure 10), en fonction des informations de souscription et de politique locale, la fonction AMF source décide d’envoyer la requête initiale vers la fonction AMF cible via le message Namf_Communication_N1MessageNotify portant le message NG-RAN Reroute Message.
Cependant, comme il ne peut y avoir qu’un seul point de terminaison N2 entre l’entité gNB et la fonction AMF pour un UE donné, la fonction AMF cible met à jour le point de terminaison auprès du gNB via le message NG AMF Configuration Update.

Figure 10 : Procédure de ré-allocation de la fonction AMF pour la gestion des transches de réseau du mobile UE : Option A
Dans le cas de l’option B (figure 11), en fonction des informations de souscriptions et de politique locale, la fonction AMF source décide d’envoyer le message NGAP Reroute NAS Message à l’entité gNB afin que celle-ci formule une nouvelle requête d’attachement vers la fonction AMF cible.

Figure 11 : Procédure de ré-allocation de la fonction AMF pour la gestion des tranches de réseau du mobile UE : Option B
Au niveau du cœur de réseau, le mobile s’enregistre sur une seule fonction AMF.
Le mobile peut demander à profiter de plusieurs tranches de réseaux (figure 12), les fonctions AMF, NSSF font parties des fonctions communes à toutes les tranches. Les fonctions PCF et NRF peuvent être communes ou spécifiques à une tranche de réseau.
Pour que le mobile puisse recevoir ou émettre des données, il faut mettre en place une session PDU. La session PDU est contrôlée par la fonction SMF, avec des règles PCF spécifiques.

Figure 12 : Les tranches de réseaux : Fonctions communes et spécifiques.
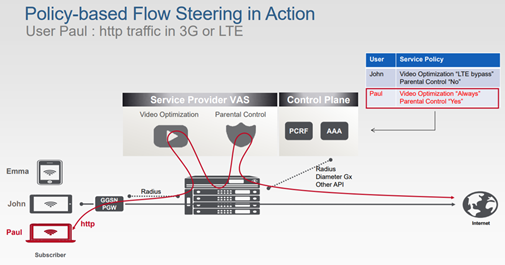
Il est aussi possible d’ajouter des fonctionnalités supplémentaires comme imposer la direction de trafic (trafic steering) en sortie du réseau de mobiles Gi-LAN afin d’apporter des services comme de l’optimisation vidéo, optimisation http, un cache CDN, un cache de réalité virtuelle, un détecteur de malware, une fonction parentale, un parefeu, …
Au niveau du mobile, le mobile fait une demande d’enregistrement auprès du cœur de réseau. Le mobile indique dans sa requête NAS les tranches de réseaux souhaitées (Requested NSSAI). Le requested NSSAI correspond soit au NSSAI configuré pour le PLMN (configured NSSAI), soit au NSSAI autorisé pour le PLMN (allowed NSSAI). Ce dernier (allowed NSSAI) a été récupéré lors d’un précédent enregistrement. Si le mobile n’a aucun NSSAI configuré pour le PLMN sur lequel il s’enregistre, alors il transmet l’information NSSAI configurée par défaut (Default configured NSSAI).
L’information NSSAI est configurée sur la mémoire non volatile du mobile. Il ne revient pas au standard 3GPP d’indiquer où est stockée cette information mais aux fabricants de terminaux. Le mobile peut contenir plusieurs informations NSSAI, chaque NSSAI est couplée à l’identifiant SUPI et est identifiée par le PLMN ID (cf. TS 24.501). Si on change l’identifiant SUPI, les informations NSSAI sont supprimées de la mémoire du terminal.
Dans le cas des smartphones, l’information NSSAI est configurée par défaut (Default configured NSSAI).
Dans le cas des terminaux IoT et URLCC, l’information NSSAI devrait être provisionnée afin de limiter l’impact de charge au niveau de la fonction AMF grand public lorsque les terminaux IoT s’allumeront.
Le mobile doit stocker les informations S-NSSAI du HPLMN. Si le mobile est enregistré sur un réseau visité VPLMN, le mobile doit aussi sauvegarder le NSSAI configuré pour ce VPLMN et doit faire la correspondance avec les S-NSSAI qu’il peut exploiter sur le réseau HPLMN. Le mapped NSSAI est utilisé en roaming pour faire la correspondance entre un S-NSSAI spécifique (128 à 255) du réseau H-PLMN et le S-NSSAI correspondant dans le VPLMN.
Lorsque le mobile demande l’établissement d’une session PDU, il transmet dans le message NAS l’information S-NSSAI souhaitée et des règles URSP (UE Route Selection Policy).
Le dernier paragraphe sera traité dans un autre article.
 Figure 1 : Des exemples de services 5G
Figure 1 : Des exemples de services 5G