

I – Généralités sur le réseau IP
I-1) Les équipements de routage et de commutation
Sur un réseau IP, la mise en relation entre un client et un serveur s’appuie sur des équipements de routage et des équipements de commutation.
Le rôle du routeur est d’acheminer chaque paquet IP au nœud suivant afin que chaque paquet puisse être transporté de bout en bout, du client IP au serveur et inversement. Avant d’être déployés sur le réseau, les routeurs doivent être configurés. La configuration permet au minima de définir les adresses IP des interfaces physiques et virtuelles du routeur et d’informer le routeur des protocoles de routage à appliquer pour acheminer les paquets IP.
Les protocoles de routage permettent à chaque routeur de récupérer des informations des routeurs voisins afin de constituer localement des informations de routage (RIB : Routing Information Base). Ainsi, les informations de routage sont actualisées pour prendre en compte l’état de chaque nœud (saturé, hors ligne, …) de manière dynamique : les routeurs échangent entre eux des informations par l’intermédiaire du protocole de routage choisi. Ensuite, les informations de routage permettent de construire une table d’acheminement (Forwarding Information Base). La table d’acheminement est exploitée par le routeur pour définir l’interface sur laquelle envoyer le paquet (adresse de destination, classe de service).
Ainsi, le protocole de routage RIB permet de constituer des règles qui sont synthétisées dans une table d’acheminement FIB afin de router le paquet IP vers le prochain saut (next-hop) selon un critère de coût (nombre de saut, débit, délai, …) géré par le RIB. L’avantage du routage dynamique est l’adaptation aux évolutions du réseau (nouvelles routes, routeur saturé ou lien défaillant) en temps réels.
Les informations de routages transmises entre routeurs dépendent du protocole de routage choisi :
- états de lien, chaque routeur s’appuie sur la qualité et les performances du lien et de la bande passante qui le relie les uns aux autres. Cet échange permet de définir une cartographie complète du réseau au niveau de chaque routeur. Ce protocole de routage s’appelle OSPF (Open Shortest Path First) et il est également utilisé par le réseau MPLS ;
- vecteur de distance se base sur le principe que chaque routeur dispose d’une table de routage indiquant, pour chaque réseau de destination, l’interface locale permettant de l’atteindre et la meilleure distance qui lui est associée (exemple de protocole RIP, EIGRP) ;
- label, les routeurs échangent des informations de label dans le contexte MPLS (LDP : Label Distribution Protocol) ;
- bordure, en bordure de deux réseaux différents (on parle de domaine), les routeurs échangent des informations de routage et d’accessibilité : BGP (Border Gateway Protocol).
Deux grandes familles de protocole sont définies : Le protocole interne domaine (OSPF, RIP, MPLS) et le protocole d’interconnexion inter domaine (BGP, EGP – Exterieur Gateway Protocol, …).
I-2) Le réseau opérateur 4G
Si on s’intéresse plus particulièrement au réseau opérateur, le réseau de transport de l’opérateur PLMN permet de fournir une interconnexion entre les différentes entités du réseau mobiles 4G. Cette interconnexion s’appuie sur deux types de réseaux principaux :
- le réseau MPLS-VPN (Multi-Protocol Label Switching – Virtual Private Network) constituant le réseau de transport du réseau EPC
- le réseau VPLS (Virtual Private Lan Service) assurant l’interconnexion de niveau 2 entre les eNB et le cœur réseau (MME, SGW)
Afin d’assurer le trafic des flux IP, le réseau MPLS utilise deux types de routeurs :
- les routeurs EDGE LSR ( Label Edge Router ou Ingress LER) sont les routeurs de passerelle vers un autre réseau (Ingress LER pour le routeur entrant et Egress LER pour le routeur sortant)
- les routeurs Core LSR constituent le domaine réseau MPLS. Ils réalisent le routage et l’étiquetage des premiers paquets et ensuite de la commutation de label.

Figure 1 : L’architecture du réseau MPLS
Le réseau VPLS est un réseau virtuel de niveau 2 qui s’appuie sur les trames Ethernet pour réaliser de la commutation Ethernet et de la commutation de label. Les tables de labels sont échangées via le protocole LDP (Label Distribution Protocol) entre les équipements du réseau VPLS.
II – Compréhension du protocole de routage
La représentation simplifiée d’un routeur est décrite sur la figure 2 par un plan de contrôle qui décide de la route et d’un plan de données pour prendre en charge le trafic. Pour les équipements de réseaux traditionnels, les plans de contrôle et le plan de données sont localisés dans le même équipement.
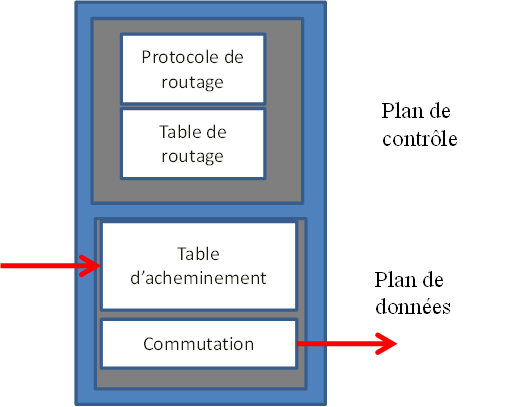
Figure 2 : La configuration simplifiée d’un routeur
La souplesse apportée par les algorithmes de routage permet d’allouer dynamiquement les routes optimales en fonction de l’évolution de charge du trafic. Cependant, cette solution souffre de deux défauts majeurs.
Le premier défaut est lié au coût d’exploitation (OPEX) pour faire évoluer l’architecture réseau. En effet, les équipements du réseau de transport (commutateurs et routeurs) sont déployés en fonction du trafic estimé. Le réseau de transport est donc surdimensionné par rapport au besoin moyen des clients mais au vu des prévisions de charge pour les années à venir, l’opérateur devra déployer et programmer d’autres équipements de routage et de commutation.
Le deuxième défaut est le manque de flexibilité du réseau vis-à-vis de l’installation de nouvelles fonctions réseaux comme l’équilibrage de charge, des pare-feux, ou le déploiement de nouveaux serveurs. Si par exemple, une entreprise multi-site souhaite installer un pare-feu uniquement et un détecteur de malware uniquement pour filtrer les connexion Internet, alors de telles modifications nécessitent soit la reconfiguration du réseau (séparation des flux entre l’accès Internet et l’accès VPN inter-site) soit la contrainte de respecter la topologie actuelle du réseau pour rajouter de nouveaux services (dans ce cas, tout le trafic VPN et Internet passera par le pare-feu et le contrôleur de malware).
Afin d’apporter de la souplesse au déploiement de services réseaux sur le réseau de transport, le SDN (Software Defined Networking) repose sur :
- l’idée de séparer le plan d’acheminement des flux IP (FIB) et le plan de contrôle constituant les informations de routages (RIB)
- d’apporter de la souplesse en donnant des ordres au plan de contrôle à partir d’API REST transmises par des applications (ingénierie de routage, Network as a Service).
Il existe deux modèles SDN :
- Programmabilité via un contrôleur. Dans ce modèle, une application donne un ordre abstrait et global à un contrôleur, qui à son tour traduit cette requête en une suite d’ordres auprès des équipements du réseau concerné.
- SDN Overlay: Création d’un réseau virtuel au-dessus du réseau physique. Dans ce modèle, les applications créent leur propre réseau « overlay », s’affranchissant des contraintes du réseau physique sous jacent. Ce dernier n’a pour mission que la simple connectivité entre les noeuds d’extrémité des tunnels, et le réseau d’overlay assure l’intégralité des services.
Programmabilité via un contrôleur
Le positionnement du SDN est donc de remplacer les routeurs et commutateurs de niveau 1 à 4 par une machine physique universelle dont le traitement des flux IP est modifié en temps réel par une couche de contrôle, appelée contrôleur SDN.
La couche de contrôle a pour rôle d’implémenter des règles sur le commutateur SDN. Les règles peuvent concerner des affectations de VLANs (port d’accès), du routage et des traitements spécifiques de services réseaux (équilibrage de charge, haute disponibilité, QoS,…)
Ainsi, l’architecture SDN est basé sur l’évolution de l’architecture suivante (figure 3):
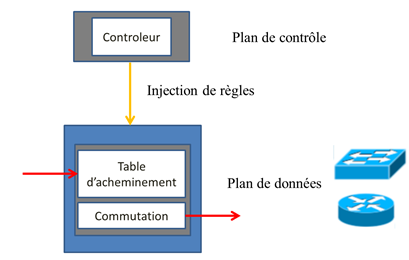
Figure 3 : Architecture SDN
Le protocole d’injection de règles SDN le plus connu est OpenFlow (version 1.0 à 1.5)
Le contrôleur est, quant à lui, piloté par le besoin des applications. On dit que le contrôleur fournit une abstraction du plan de transport aux applications. La notion d’abstraction signifie que le contrôleur offre des interfaces programmables aux applications réseaux (les interfaces sont nommées API) et le contrôleur se charge de piloter le plan de données en injectant des règles d’acheminement spécifiques répondant aux besoins des applications sans que les applications connaissent ces règles.
Ainsi, comme le montre la figure 4, la couche d’abstraction du contrôleur comporte une interface de programmation (interface Nord) qui fournit des fonctions génériques et banalisées de manipulation du réseau de transport en cachant les détails techniques des entités du réseau. Ceci permet à une application d’informer le contrôleur des besoins de traitement de flux de manière générale en faisant abstraction des détails technique du matériel.
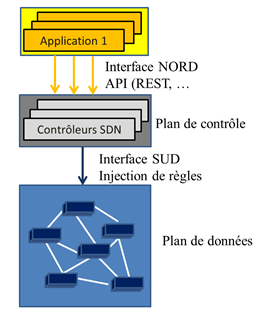 Figure 4 : Le principe du SDN
Figure 4 : Le principe du SDN
Le contrôleur dispose d’une interface nord appelé Northbound API afin de proposer des API de haut niveau aux applications SDN. Les applications SDN peuvent être une demande de gestion du réseau, un contrôle d’accès, une priorité de service à mettre en œuvre, …
Le plan de contrôle va orchestrer la demande des applications en transmettant via l’interface sud les tables d’acheminements correspondantes. Les protocoles utilisés sur l’interface sud peut être le protocole CLI (Command Line Interface), le protocole OpenFlow, ou d’autres protocoles (NETCONF/YANG, …)
Le terme d’orchestration désigne le processus qui permet au contrôleur de satisfaire les demandes de service de plusieurs clients selon une politique d’optimisation pour chaque service.
Le plan de données ou plan usager est chargé de l’acheminement (forwarding) du trafic des utilisateurs et de l’application de politique de trafic (parefeu, VLAN, …) dont les règles ont été transmises par le contrôleur. La politique réseau étant définie par les applications.
SDN Overlay
Principe de l’Overlay
Le réseau overlay est une solution initialement dédiée aux hébergeurs de Cloud Center afin que deux serveurs de l’hébergeur, physiquement éloignés, puissent communiquer entre eux via un réseau de transport opérateur (réseau d’interconnexion externe aux hébergeurs donc non modifiable).
Les réseaux Overlay (over-layer) signifie construire un réseau virtuel de couche 2 au-dessus d’un réseau de couche 3 : Les paquets du réseau sont encapsulés puis routés à travers l’infrastructure existante. Un des protocoles proposé est le VxLAN (Virtual eXtensible LAN) proposé dans le RFC 7348. Il encapsule les trames Ethernet dans un datagramme UDP.
A l’origine, cette solution a été proposée pour faciliter l’interconnexion des serveurs de cloud qui sont basés sur le principe de virtualisation : un hébergeur dispose de plusieurs salles de serveurs. Chaque serveur est une machine physique pouvant recevoir plusieurs machines virtuelles (VM). Afin de partager les ressources physiques (RAM, CPU, cartes réseau, …), il est nécessaire d’installer sur le serveur un logiciel nommé hyperviseur. Un hyperviseur (VMM : Virtual Machine Monitor ou Virtual Machine Manager) est un moniteur de machines virtuelles installé directement sur la machine physique (hyperviseur bare metal) ou sur un système d’exploitation. Son rôle est de contrôler l’accès au matériel et de partager les ressources physiques entre toutes les machines virtuelles (VM : Virtual Machine).
L’hyperviseur virtualise l’interface de réseau physique et la partage entre toutes les machines virtuelles. Chaque VM dispose de sa propre adresse MAC et adresse IP. Les VMs sont configurées en mode pont, NAT ou sont isolées des autres VMs (Host Only ou réseau privé). Le mode host only permet de créer un réseau privé entre la VM et le machine hôte.
La virtualisation du réseau coordonne par conséquent les commutateurs virtuels dans les hyperviseurs du serveur et les services réseaux pour les VM connectées.
L’hyperviseur réalise ainsi un commutateur virtuel permettant de connecter les VM les unes aux autres. Le commutateur virtuel supporte le VLAN, mais le protocole 802.1Q limite à 4096 le nombre de VLAN. Lorsque l’hébergeur de solution cloud souhaite exploiter le réseau IP opérateur pour transmettre des paquets IP entre deux serveurs situés sur le même réseau virtuel, il est nécessaire d’encapsuler les trames dans une couche supérieure.
Les hébergeurs exploitent le protocole VxLAN, chaque VM sur une machine physique est identifiée par un identifiant réseau VxLAN sur 24 bits, nommé VNI. L’hyperviseur de chaque serveur gère l’encapsulation et la décapsulation des trames contenues dans les VxLANs (VTEP : VxLAN Tunnel EndPoint).
Supposons qu’une machine virtuelle située sur un réseau virtuel (VxLAN) dans un serveur physique souhaite transmettre des données vers une machine virtuelle située dans un autre serveur physique (VxLAN). La machine virtuelle source construit sa trame Ethernet avec les champs suivants :

Figure 5 : L’architecture réseau entre deux serveurs interconnecté par le réseau IP opérateur
La figure 6 représente l’encapsulation et les entêtes associées :
Trame Ethernet VM: VxLAN ID/Mac Dest/Mac Src VM/ IP Src VM/ Ip Dest VM/ TCP ou UDP Data
L’hyperviseur de la machine virtuelle encapsule la trame Ethernet dans la couche UDP :
MAC VTEP Dest ou MAC GW/ MAC VTEP Source/IP VTEP source/IP VTEP Destination/ UDP/Data contenant laTrame Ethernet VM.
 Figure 6 : L’encapsulation VxLAN
Figure 6 : L’encapsulation VxLAN
Nous venons de voir l’overlay, mais pas encore le SDN.
SDN Overlay ou Overlay réseau programmable
Nous savons que le principe du SDN réside dans la séparation du plan de contrôle et du plan utilisateur. Dans le cas du SDN overlay, le réseau physique sous-jacent ne peut pas être contrôlé, le SDN s’applique donc au réseau overlay.
Les datacenters doivent aussi être flexibles et gérer au mieux les flux de réseaux. La programmabilité s’exprime surtout ici avec l’orchestration des ressources : comment coordonner intelligemment le processus de mise à disposition d’infrastructure en entreprise. Ainsi, la virtualisation permet à l’intelligence de l’infrastructure des hébergeurs Cloud de contrôler et de déployer automatiques les serveurs. Les éléments de l’infrastructure (stockage, calcul, mis en réseau) sont virtualisés et regroupés en pools de ressources. De plus les applications doivent être mobiles et répliquées sur un Cloud distant afin de permettre une reprise après sinistre.
L’utilisation d’une plate-forme de gestion du Cloud (CMP – Cloud Management Platform) permet de provisionner des réseaux virtuels en activant les services réseaux et les services de sécurité virtuels en fonction des charges de travail.
Il existe plusieurs solutions virtuelles ( VMware NSX, Midokura MidoNet et Nuage Networks) afin de contrôler dynamiquement les routeurs virtuels, les commutateurs virtuels grâce à un contrôleur de service virtualisé qui permet également de déplacer, créer ou détruire un VM afin de répondre au mieux au besoin du client
Le rôle du SDN est donc d’orchestrer les VMs afin d’adapter les ressources de l’hébergeur cloud (Amazon SE3, …) au besoin du client en assurant la fiabilité de l’interconnexion, l’accès rapide au données, ….
Merci à Sébastien Couderc d’avoir accepté de relire cet article
Bonjour,
merci pour cet article très clair.
J’ai une question à laquelle jvous avez peut être la réponse :Après qu’un contrôleur SDN a fait appliquer une configuration aux équipements, si le réseau change (réduction de la bande passante, panne), une nouvelle configuration est-elle automatiquement repoussée vers les équipements ou une nouvelle demande émanant de la couche applicative est nécessaire.
Merci de votre retour.
Le contrôleur établi une liaison sécurisée avec l’ensemble des entités d’acheminement, si l’un d’entre eux tombe en panne, il est informé et doit apporter une nouvelle configuration. S’il n’est pas possible, je suppose qu’il envoie une information de charge (via une API) à la couche applicative.
Mais je n’ai pas les compétences pour vous assurer de cette réponse à 100%
Bonjour
cela semble en effet plutôt logique, mais je n’ai rien de plus à apporter. Merci pour ce complément
Merci ! Ton explication est claire et concise
Merci beaucoup, néanmoins je ne suis pas issu d’une formation réseau, j’espère donc que l’article est juste.
Bonjour comment vous comment peut-on prendre en charger le switch virtuelle avec le SDN? est-il possible de faire une administration avec les IoT ?
Merci
comment peut-on administré le réseau IoT via le SDN.