Nous travaillons au sein du Service Etudes et Prospective du Pôle Datar de la Région Nouvelle-Aquitaine sur la géographie des taux de chômage, à différentes échelles géographiques (départements, zones d’emploi, EPCI), ainsi que sur le lien entre la dynamique de l’emploi et la dynamique du chômage. L’objectif est d’identifier des territoires qui sont dans une situation relative plus problématique, de documenter progressivement les déterminants de leur situation, pour agir ensuite plus efficacement et réduire les problèmes auxquels ils sont confrontés.
Nous travaillons au sein du Service Etudes et Prospective du Pôle Datar de la Région Nouvelle-Aquitaine sur la géographie des taux de chômage, à différentes échelles géographiques (départements, zones d’emploi, EPCI), ainsi que sur le lien entre la dynamique de l’emploi et la dynamique du chômage. L’objectif est d’identifier des territoires qui sont dans une situation relative plus problématique, de documenter progressivement les déterminants de leur situation, pour agir ensuite plus efficacement et réduire les problèmes auxquels ils sont confrontés.
Ce travail a donné lieu à la production d’une première note disponible sur le portail des territoires de la Région, à laquelle vous pouvez accéder en cliquant ici. On mobilise le taux de chômage au sens du recensement, dont la définition est plus large que la définition traditionnelle, elle inclut pour partie ce que l’on appelle le halo du chômage (sont notamment comptabilisées les personnes qui se déclarent spontanément à la recherche d’un emploi).
Si le taux de chômage évolue avec le temps, à la hausse où à la baisse, l’analyse de la géographie des taux de chômage révèle une forte inertie : la situation relative des territoires bouge peu, ceux à plus fort taux de chômage que la moyenne restent globalement à plus fort taux de chômage, ceux à plus faible taux restent à plus faible taux. On a du mal à faire converger les taux à la baisse. Dans la note, on montre par exemple que les taux de chômage observés au recensement millésime 2012 (qui couvre la période 2010-2014) à l’échelle des EPCI “expliquent” 93% des taux de chômage du recensement millésime 2017 (qui couvre la période 2015-2019). Quand je dis “explique”, il s’agit en fait d’une corrélation, d’où les guillemets : ce qui est calculé, c’est le coefficient de corrélation entre les taux de chômage d’une année et ceux de l’autre année, un coefficient de 0,93 signifie que 93% des différences géographiques observées en 2017 peuvent être expliquées par les différences observées en 2012.
En complément du document, j’ai analysé depuis les taux de chômage (au sens de l’organisation internationale du travail cette fois, pas au sens du recensement) à l’échelle des départements : les taux 2010 “expliquent” 88% des taux 2019. Ceux de 2003 en “expliquent” encore 75%. Plus on s’éloigne dans le temps, moins le lien est important, heureusement, mais les taux de 1982 “expliquent” encore, malgré tout, 31% des taux de 2019.
 Les deux graphiques ci-dessus représentent les nuages de points départementaux, chaque numéro correspond au numéro du département, les numéros en rouge correspondant aux départements de Nouvelle-Aquitaine. On voit la force du lien entre les taux de 2010 et ceux de 2019, et le lien beaucoup plus faible entre les taux 2019 et ceux de 1982 (pour information, il n’y a pas eu de changement radical dans la géographie des taux de chômage entre 2019 et 2020, la corrélation dépasse les 95%).
Les deux graphiques ci-dessus représentent les nuages de points départementaux, chaque numéro correspond au numéro du département, les numéros en rouge correspondant aux départements de Nouvelle-Aquitaine. On voit la force du lien entre les taux de 2010 et ceux de 2019, et le lien beaucoup plus faible entre les taux 2019 et ceux de 1982 (pour information, il n’y a pas eu de changement radical dans la géographie des taux de chômage entre 2019 et 2020, la corrélation dépasse les 95%).
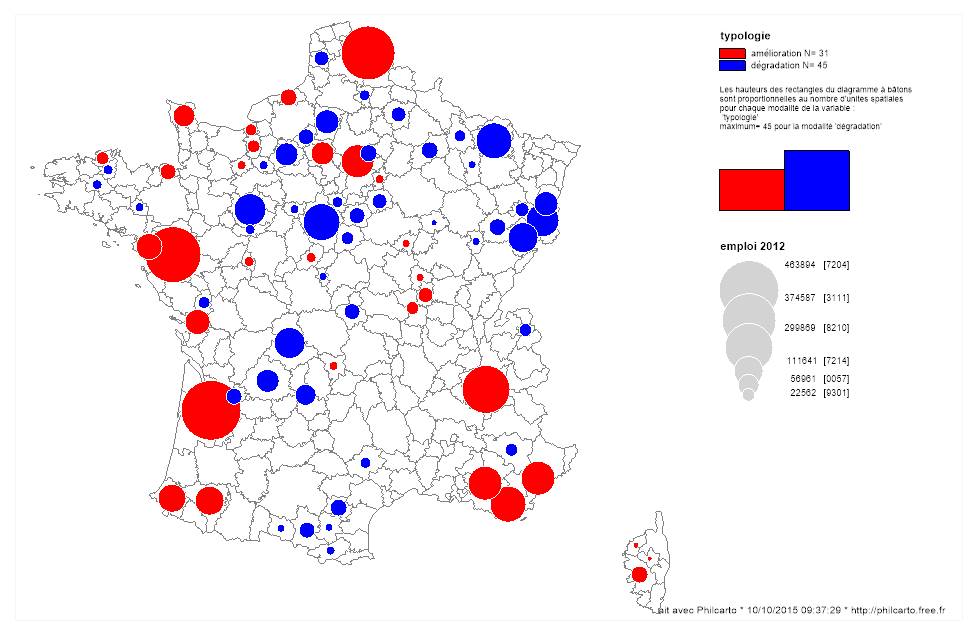
Une forte inertie, donc, mais quelques mobilités au sein de la distribution des taux de chômage. S’il n’y avait pas de mobilité, les coefficients seraient de 100%. On peut donc identifier les territoires qui ont connu les plus fortes évolutions dans leur situation relative, soit à la hausse (dégradation relative du taux de chômage), soit à la baisse (amélioration relative du taux de chômage). Sur cette base, dans le document, on identifie les territoires de Nouvelle-Aquitaine qui non seulement ont des taux de chômage élevés, mais qui en plus connaissent une dégradation relative de leur situation, ce qui pourrait justifier une attention plus importante.
L’autre élément sur lequel on insiste ensuite est la très faible relation entre croissance de l’emploi et dynamique du chômage : ce n’est pas parce qu’on créé beaucoup d’emplois sur un territoire que le nombre de chômeurs ou le taux de chômage baissent, et ce n’est pas parce qu’on en créé peu, voire que l’emploi diminue, que le taux de chômage augmente. On observe en fait toutes les situations : croissance de l’emploi et du chômage, croissance de l’emploi et baisse du chômage, baisse de l’emploi et hausse du chômage, baisse de l’emploi et du chômage. Ceci peut résulter d’un large ensemble de déterminants : des zones attirent de la population, créé de l’emploi, mais pas suffisamment pour pourvoir les besoins, d’où la hausse du chômage ; d’autres zones, parfois les mêmes, proposent des emplois saisonniers ou intérimaires, ce qui peut résulter en une hausse du taux de chômage annuel moyen ; dans d’autres cas, les emplois créés ne peuvent être pourvus par les personnes au chômage, parce que ces personnes ne disposent pas des compétences recherchées, ou qu’elles sont confrontées à d’autres problèmes (logement, transport, santé, garde d’enfants, …) ; des territoires à croissance négative de l’emploi voient le chômage diminuer parce que les personnes qui sont à la recherche d’un emploi quittent le territoire ; etc.
En collectant des éléments plus précis sur la situation des territoires, on doit pouvoir mieux agir. Par exemple, lorsqu’on se trouve dans un territoire à fort chômage et faible création d’emploi, on peut se dire que des actions en termes de développement économique sont souhaitables. Quand on se trouve dans des territoires à forte dynamique d’emploi, ce n’est sans doute pas la priorité, des actions en termes de formation, d’orientation, voire de santé, de mobilité, de logement, …, sont préférables, en fonction des problèmes plus précis identifiés. C’est à ce travail d’identification plus précise des problèmes à traiter auquel nous allons nous atteler dans les prochains mois, en nous appuyant notamment sur la connaissance terrain des collègues de l’institution régionale et des acteurs des territoires concernés.