Pour continuer l’étude de la double connexion, je vous propose un call-flow. Ce call Flow termine l’étude de la Double connexion.
Le document est une lecture de la norme (Spécification 3GPP 38.912) dans un contexte ou les équipementiers testent leurs solutions. Mettez en doute chacune de mes affirmations, et n’hésitez pas à me corriger si vous détectez des erreurs.
Je me suis aussi inspiré du blog de Martin SAUTER : https://blog.wirelessmoves.com/2018/08/5g-en-dc-lets-talk-about-signaling-srb1-2-srb-3-split-srb.html
2-3) Call Flow – EN-DC NSA : Split-Bearer option 3X (Création d’un support entre le cœur réseau 4G (EPC) et une station de base en-SgNB)
Le call flow présente le ré-établissement d’un support (bearer) entre l’entité SGW et la station de base secondaire en 6 étapes pour le sens descendant uniquement (se référer au premier article).
On considère ici le cas de l’option 3X :
- le bearer montant est maintenu au niveau de l’entité eNB
- le bearer descendant est configuré vers l’entité S-en-gNB (SCG Configuration) et partagé entre les deux stations de base par la station de base secondaire (SN Terminated Split-bearer)
On part évidemment dans l’hypothèse que le terminal est déjà attaché au réseau, et que le support PDN par défaut existe. Cette hypothèse permet d’avoir l’identifiant TEID UL du SGW stocké au niveau de l’entité MME, ce qui est nécessaire lors du ré-établissement de support (entre le SGW et l’eNB). Le TEID S1-UL est l’identifiant de tunnel qui sera inscrit dans le contexte de l’entité eNB (donc le Master) permettant d’étiqueter le flux montant (association avec l’identité temporaire du terminal et la QoS correspondante). Ainsi, les données émises par le terminal UE vers l’entité eNB (lien montant) et identifiées par l’identifiant radio C-RNTI seront transférées par l’entité eNB vers l’entité SGW avec l’identifiant d’acheminement TEID S1-UL (et l’adresse IP du SGW). Pour l’entité SGW, le tunnel TEID a été construit et correspond à l’identifiant du tunnel par défaut monté lors de la procédure d’attachement (PDN Connectivity).
Dans cet exemple, on suppose la création d’un support entre l’entité SGW et l’entité en-gNB. Ce support peut (mais pas obligatoire) remplacer le support existant entre l’entité SGW et l’entité eNB. On se positionne donc sur l’option 3x.
On suppose également que la station de base eNB a activé la cellule secondaire en-gNB (procédure X2AP Secondary Cell activation). Ainsi, la station de base eNB émet la liste des cellules 5G présentes dans le message de SIB2 permettant au terminal UE d’être informé de la présence du réseau 5G (et d’afficher le logo 5G).
Etape 1 : Connexion radio et cœur réseau en 4G
Le terminal UE fait une demande de connexion radio vers l’entité eNB, à laquelle la station de base répond en indiquant l’identifiant radio C-RNTI pour la connexion LTE.
A partir de l’identifiant C-RNTI, le mobile transmet une requête RRC d’établissement de support (RRC Connexion Request) en indiquant la raison de sa demande (Establishment cause).
La station de base eNB répond au terminal UE par le message RRC Connection SETUP (Support de signalisation SRB0).
Le terminal UE encapsule le message NAS (Service Request) dans le message RRC Connection Setup Complete (support de signalisation SRB1) à destination de la station de base eNB. Il indique au réseau qu’il supporte la fonction DC 4G/5G en positionnant le bit DCNR du message UE Capability Network à 1. Le message est chiffré avec la clé NAS (MME).
La station de base eNB transmet le message NAS à l’entité MME. Si l’entité MME ne parvient pas à déchiffrer le message, il procède à l’authentification et à la mise en sécurité NAS. L’authentification nécessite l’apport de l’entité HSS.
Cette procédure est optionnelle car si le message NAS est déchiffré par l’entité MME, l’authentification est alors validée.
 Etape 2 : Mise en place du support pour le lien montant UL entre l’entité eNB et l’entité SGW et du support radio bi-directionnel entre le terminal UE et la station de base (récupération des capacités du terminal et mise en sécurité AS sur l’accès LTE)
Etape 2 : Mise en place du support pour le lien montant UL entre l’entité eNB et l’entité SGW et du support radio bi-directionnel entre le terminal UE et la station de base (récupération des capacités du terminal et mise en sécurité AS sur l’accès LTE)
A partir de cette étape, tous les messages NAS échangés entre le terminal UE et l’entité MME sont chiffrés.
L’entité MME transmet à la station de base eNB via le message Initial Context Setup Request :
- les capacités QoS maximales (extended UE AMBR);
- l’identité QoS de la requête de service ;
- l’identité du support radio (RAB Id) ;
- le numéro de tunnel SGW TEID UL permettant d’identifier le lien UL au niveau du SGW ;
- la clé de sécurité (KeNB) permettant de dériver les clés de chiffrement et d’intégrité sur le lien radio
A partir du message Initial Context Setup Request, l’entité eNB doit :
- mettre en œuvre l’établissement du support E-RAB configuré par l’entité MME ;
- sauvegarder le profil de QoS de l’utilisateur (UE-AMBR) ;
- sauvegarder la liste de restriction de handover (handover restriction list IE);
- transmettre les valeurs contenues dans chaque élément d’information E-RAB ID IE et NAS-PDU IE pour chaque support d’accès radio (RAB) ;
- sauvegarder la capacité du terminal UE (exemple : IoT et le mode CE)et ses capacités de sécurités (UE security capacities et NR UE security capacities ) .
La capacité du mobile à supporter la double connexion 4G/5G est signalée à l’entité MME dans le message d’information : Extended UE-AMBR Downlink and Uplink Information Elements. Ces informations sont connues par le MME et récupérées à partir de l’entité HSS lors de la demande d’attachement de l’utilisateur.
Si la liste de restriction de handover est transmise, l’entité eNB pourra sélectionner la cellule secondaire SCG pendant l’opération de Double Connexion.
En absence d’information sur le terminal de la part de l’entité MME, la station de base demande des informations sur les capacités radios supportées par le terminal UE (UE-CapabilityRequest = eutra, eutra-nr, nr).
Le terminal UE informe la station de base MeNB (on parle maintenant de MeNB car on se prépare à la double connexion) qu’il supporte le mécanisme DC NR et indique les bandes supportées dans le message UE-CapabilityRAT-ContainerList {rat-Type EUTRA-NR, ue-CapabilityRAT-Container = UE-MRDC-Capability}, SupportedBandListNR-r15.
Les informations récupérées par l’entité MeNB sont transmises à l’entité MME par le message UE Capability Information Indication portée par l’application S1 AP
A l’issu du message Initial Context Setup Request, l’entité eNB :
- sécurise le lien radio ;
- établi le lien radio avec le terminal UE via le message RRC Connection Reconfiguration (SRB2)
L’entité MeNB configure le terminal UE des mesures à réaliser (Objects Measurements) sur les liens radios 4G/5G et active le lien radio (support Data) via le message RRC Connexion Reconfiguration en fournissant au terminal UE le numéro de séquence PDN et l’identifiant du support radio (EPS Radio Bearer Identity).
Le terminal UE confirme l’activation du support par défaut (RRC Connection Reconfiguration Complete).
A partir de ces messages RRC Connection Reconfiguration, le support radio data (RAB) est établi dans les deux sens entre le terminal UE et la station de base. Le terminal peut donc recevoir ou transmettre des données avec la station de base.
Une fois la connexion établie (et sécurisée), l’entité eNB acquitte la demande d’établissement de support du MME par le message Initial Context Setup Response. Ce message contient la liste des supports RAB (E-RAB list) qui sont établis par l’entité MeNB.
Etape 3 : Configuration du support S1-U pour le lien descendant DL
L’entité MeNB transmet à l’entité MME le message Initial Context Setup response en réponse au message Initial Context Setup request transmis précédemment par le MME pour la demande d’établissement du support. C’est à ce moment que l’entité MeNB transmet à l’entité MME l’identifiant TEID DL qui sera utilisé par le SGW pour l’acheminement du trafic descendant vers la station de base MeNB (et à destination du terminal UE).
L’entité MME créée une entrée dans la table d’acheminement de l’entité SGW avec l’identité TEID DL et l’adresse IP de l’entité eNB pour le contexte de transfert en DL. A partir de ce moment, le trafic descendant est possible au niveau du cœur réseau et donc de bout en bout.

A ce stade, le support EPS par défaut est établi permettant une connexion bi-directionnelle entre le terminal UE, la station de base maîtresse MeNB, et les entités du plan de transport SGW/PGW.
Etape 4 : Préparation à la Double Connexion 4G/5G (option 3)
La procédure d’ajout d’un nœud secondaire est controlée par l’entité MeNB et la requête est soumise à la station de base secondaire via le message SgNB Addition Request. Cette procédure permet à la station de base maitresse de définir le type l’option DC (3/3a/3x) en transmettant les identifiants de tunnel TEID pour le support MCG/SCG ou en demandant à l’entité SgNB de fournir les identifiants de tunnel pour le support SCG.
Si on revient sur la figure 8, il y a beaucoup d’options possibles :
- MCG bearer (option 3a);
- SCG bearer (option 3a);
- MN Terminated Split-bearer (option 3);
- SN Terminated Split Bearer (option 3x).
Chaque support est transmis du cœur de réseau vers l’entité MeNB ou vers l’entité SgNB ou vers les deux. On va nommer la station de base en-gNB sous le terme SgNB.
A titre d’exemple, le support (bearer) peut être reçu par l’entité SgNB et les paquets DL sont transmis de l’entité SgNB vers l’entité MeNB. La norme précise que si la requête SgNB Addition Request demande la configuration entre le coeur de réseau 4G et l’entité S-gNB alors l’entité S-gNB transmet l’identifiant de tunnel S1 SGW TEID DL à l’entité MeNB pour modifier le tunnel descendant avec l’entité SGW. Pour terminer le tunnel descendant vers l’entité eNb, ce dernier transmet l’identifiant de tunnel MeNB DL GTP TEID at MCG IE pour le tunnel entre l’entité SgNB et MeNB. Dans ce cas, l’entité SgNB doit utiliser ce numéro de tunnel en tant qu’acheminement en DL (DL X2-U) pour délivrer les paquets DL PDCP.
Pour résumer :
- avant l’ajout d’un noeud secondaire, le tunnel data s’effectue entre le CN et l’entité MeNB.
- Après l’ajout du noeud secondaire, l’entité SGW aura modifié sa table de commutation vers l’entité SgNB (identifiant S1 SGW DL) et l’entité SgNB aura crée une table dans sa table de commutation vers l’entité MeNB (MeNB DL GTP TEID).
Mais pendant la phase de changement de commutation de tunnel entre l’étape 1 et l’étape 2, les paquets transmis du SGW vers l’entité MeNB seraient perdus? Il faut donc assurer un tunnel temporaire entre l’entité MeNB vers l’entité SgNB des données arrivant du SGW. Ce numéro de tunnel est transmis dans le message SgNB Addition Request, par le paramètre MeNB UL GTP TEID at PDCP IE. Pour que le tunnel soit complet, l’entité SgNB va répondre dans le message SGNB ADDITION REQUEST ACKNOWLEDGE le numéro de tunnel du SgNB (Secondary SgNB DL GTP TEID at SCG IE) en indiquant le mode de transmission (duplication ou non).
Nous allons maintenant étudier les requêtes, cependant, avant d’établir une double connexion, l’entité MeNB analyse les mesures effectuées par le terminal UE.
Dans le précédent message de signalisation RRC Connexion Reconfiguration SRB2, l’entité MeNB avait transmis au terminal UE les éléments de mesure (measurement objects) à réaliser. Dans le cas d’un terminal compatible DC LTE/NR, la station de base maîtresse MeNB demande au terminal UE d’écouter les signaux de références NR.
Le terminal UE se synchronise sur les signaux de références PSS/SSS 5G et mesure le niveau de puissance reçu à partir des canaux de références DM-RS (transmis avec le bloc SSB : bloc de synchronisation et BCCH) et le signal de référence CSI-RS. A cette étape, le terminal ne cherche pas à établir un support de signalisation SRB avec la station de base secondaire SgNB, mais uniquement à remonter la qualité du lien radio NR.
Si la mesure du lien radio réalisée par le terminal UE et transmise à la station de base MeNB permet d’établir une double connexion, la station de base maitresse MeNB demande l’ajout d’un second nœud radio avec la station de base secondaire 5G SgNB.
Nous allons étudier la procédure d’ajout du nœud secondaire (procédure SgNB Addition). Nous verrons ensuite la procédure de modification du nœud secondaire. La procédure d’ajout d’un nœud secondaire s’effectue par un échange d’information sur le routage et la QoS des supports, et la procédure de modification permet de changer la configuration.
La requête SgNB Addition Request transporte les informations de configuration du support (TEID, E-RAB Parameters), les capacités du terminal et les informations de sécurité de la couche radio : Pour le chiffrement, la station de base MeNB indique au terminal si le chiffrement sera réalisé par l’entité PDCP 4G ou par l’entité PDCP 5G.
En fonction de l’option DC choisi (ou imposée) par l’entité MeNB, les paramètres échangés entre la station de base maitresse MeNb et secondaire définissent :
- le routage du support (bearer) soit au niveau du cœur réseau (MCG/SCG), soit au niveau de l’accès radio (MeNB ou SgNB pour le split-bearer) ;
- l’allocation de ressource et la QoS attendue sur le support MCG ou le support SGC (Request MCG E-RAB Level QoS Parameter IE ou Request SCG E-RAB Level QoS Parameter IE).
Ainsi, les paramètres transmis lors de la procédure d’ajout d’un nœud secondaire concernent :
- les caractéristiques du support radio E-RAB (E-RAB Parameters, TNL address information) ;
- les dernières mesures radios correspondant à l’entité SgNB
- les informations de sécurité pour l’établissement du lien de signalisation SRB3 (option si la configuration SRB-splitUL est activée)
- les informations
- de configuration SCG avec les capacités du terminal UE (UE capabilities and UE capability coordination result) : les identifiants de tunnel SgNB DL TEID
- de configuration Split-bearer avec les capacités du terminal UE : les identifiants de tunnel dans le cas de l’établissement d’un support nécessitant un transfert via l’interface X2-U entre les nœud maître et secondaire (MN et SN) pour le split bearer : X2-U TNS address information (MeNB UL TEID)
- les caractéristiques de la QoS dans le cas de l’option de split-bearer.
- maximum supportable QoS level
Si la station de base secondaire accepte la demande d’ajout de nœud, celle-ci répond par un message SgNB Addition Request acknowledge et transmet :
- l’allocation des ressources radios nécessaires pour le transport des flux ;
- décide de la mise en place de l’agrégation de porteuse en attribuant des ressources sur la cellule principale PScell (cellule de service ou Serving Cell) et éventuellement les cellules secondaires pour l’agrégation de porteuses sur l’entité gNB (SGS Scells) ;
- selon l’option choisi (option 3a ou option 3x) :
- fournit les identifiants d’adressage sur le lien X2-U dans le cas ou du trafic doit être transmis entre l’entité MeNB et l’entité SgNB.
- Selon le mise en place de ressources radio SCG, l’entité SgNB fournit la configuration des ressources
Dans le cas de l’option de configuration du support SCG ou de l’option 3x (split-bearer) sur l’entité SgNB, le support radio est géré par l’entité PDCP de la station de base secondaire SgNB. Dans ce cas, l’entité maîtresse MeNB propose la modification d’acheminement d’un certain nombre de supports sur la liaison descendante. Les différents supports à modifier sont indiqués dans les éléments d’informations DL forwarding IE du champ E-RAB to Be Added Item (tableau 1).

Tableau 1 : Les champs d’information de la requête en-SgNB addition Request
La liste des supports radios E-RAB pris en charge par l’entité secondaire SgNB est transmise à la station de base maitresse MeNB via le message SgNB Addition Request Acknowldge.
L’entité SgNB valide en totalité ou partiellement la demande de l’entité MeNB. Les supports pris en charge par l’entité SgNB sont indiqués à l’entité SgNB dans l’élément DL Forwarding GTP Tunnel Endpoint du champ E-RAB to Be Added Item (tableau 2).
L’allocation de ressource au niveau de la station de base secondaire SgNB permet :
- d’établir la cellule primaire Pscell et éventuellement d’autres SCG Scells
- Dans le cas de l’option 3 ou 3x nécessitant un support sur l’interface X2-U
- l’entité SgNB fournit les informations d’adressages X2-U TNS pour l’acheminement des données
- Dans le cas d’une requête de support radio SCG radio
- l’entité MeNB fournit la configuration des ressources radio SCG
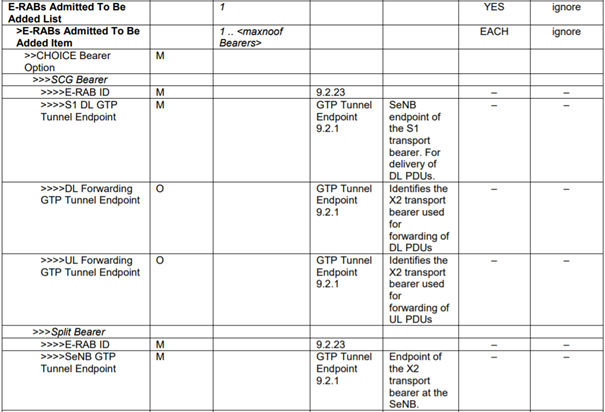
Tableau 2 : Les champs d’information de la requête SgNB addition Request Acknowledge
Pour résumer, la configuration (pour chaque support radio) de la table d’acheminement correspondant à l’option 3/3a/3x de la double connexion est transmis par l’entité secondaire SgNB vers l’entité MeNB dans le message SgNB Addition Request Acknowldge :
- SCG Bearer
- une identité de tunnel S1 DL GTP TEID ;
- une identité de tunnel DL Forwarding pour le transfert du bearer dédié à l’eNB (et non partagé, le tunnel arrive à l’entité S-gNB et est entièrement transmis à l’entité MeNB);
- une identité de tunnel UL Forwarding pour transmettre les données reçues par l’entité MeNB vers le CN (point d’ancrage SgNB)
- Split-bearer
- une identité de tunnel S1 DL Forwarding GTP TEID
- une identité de tunnel X2 DL GTP TEID pour les données partagées au niveau de l’entité SgNB et destiné à l’entité MeNB.
Dans le cas de l’option 3a (avec le SCG bearer défini au niveau de l’entité en-gNB) et dans le cas de l’option 3x (le split bearer est ancré au niveau du en-gNB), l’entité MeNB devra communiquer au MME l’identifiant de tunnel S1 DL TEID pour l’établissement du bearer S1-U entre l’entité en-gNB et l’entité SGW.
Dans le cas du SCG bearer défini au niveau de l’entité MeNB ou dans le cas du split bearer au niveau de l’entité eNB (option 3), la modification d’acheminement porte sur le routage de tunnel TEID entre l’entité en-gNB et l’entité MeNB : la station de base maîtresse MeNB va transmettre à l’entité en-gNB l’identifiant de tunnel X2 UL TEID pour l’établissement du bearer X2-U entre l’entité S-gNB et l’entité SGW et l’entité SgNb envoie l’identifiant de tunnel X2 DL TEID à l’entité MeNB.
Si la station de base maitresse MeNB a demandé à l’entité SgNB la configuration d’un support MCG en transmettant dans le message SgNB Addition Request la ressource MeNB DL GTP TEID at MCG, alors l’entité SgNB doit utiliser l’adresse X2-U pour les paquets PDU PDCP dans le sens descendant.
A partir du moment où les règles d’acheminement ont été négociées entre l’entité maitresse MeNB et l’entité SgNB, la station de base MeNB transmet au terminal UE la nouvelle configuration radio. Le contenu de la configuration du lien radio est transmis par l’entité MeNB au terminal UE via le message RRC Connection Reconfiguration (SRB2). Ce message transporte la requête NR RRC Connection Reconfiguration
A partir de ce message, le terminal UE récupère la configuration du lien RACH avec l’entité SgNB et l’identité C-RNTI pour l’accès 5G.
Le terminal UE transmet le message RRC Connection Reconfiguration Complete à l’entité MeNB. Ce message transporte la requête NR RRC Reconfiguration Complete destiné à l’entité SgNB. La station de base maîtresse transfert ce message à l’entité SgNB via l’interface X2 à travers le message SgNB Reconfiguration Complete. La station de base maitresse transmet ensuite le numéro de séquence SFN des supports SCG qui seront transférés vers l’entité SgNB.
A ce stade, le support radio NR n’est pas encore finalisé, mais les données du support reçue au niveau de l’entité MeNB et provenant de l’entité SGW sont routées et bufférisées au niveau de l’entité SgNB.

Etape 5 : Création d’un support SCG entre le cœur de réseau 4G et la station de base SgNB
Dans le cas de la création du support SCG, la station de base maîtresse demande à l’entité MME de modifier la table d’acheminement au niveau de l’entité SGW afin d’acheminer les supports vers la station de base SgNB et non plus vers la station de base maîtresse MeNB.
L’entité MME modifie la table d’acheminement au niveau du SGW par une requête de modification de support (Modify Bearer). Une fois la modification portée, l’entité SGW confirme à l’entité eNB la suppression du bearer, ce dernier transfère alors les données subséquentes vers l’entité SgNG en attendant l’établissement du lien radio NR.
Dans le cas de l’option du split bearer option 3, l’entité MME n’est pas informé de la modification de la demande de bearer S1-U.
Dans le cas de l’option du split-bearer option 3x, l’entité MME est informé de la modification du point de terminaison du bearer S1-U.

Etape 6 : Etablissement de l’accès radio 5G
Le terminal UE se synchronise sur l’accès radio NR avec l’entité SgNB à partir des signaux de synchronisation PSS et SSS. A partir du PSS et SSS, le terminal UE récupère le numéro de la cellule NR PCI.
La lecture du MIB permet au mobile de se synchroniser avec le début de la trame.
Le terminal UE fait une demande d’accès radio via la procédure d’accès aléatoire RACH. Le préambule aléatoire est déterminé par la lecture du MIB (accès avec contention) ou à partir des informations transmises au mobile lors de l’étape 4 pour un accès sans-contention (message RRC Connection Reconfiguration).
La station de base secondaire fournit l’identifiant temporaire RA-RNTI puis alloue des ressources radio NR au terminal (DCI 1.0). Le terminal acquitte par une réponse en UL (PUSCH) et des données sur le lien montant.
La connexion bidirectionnelle est établie entre le terminal UE et le cœur de réseau SGW via l’entité SgNB.
Régulièrement, le terminal UE transmet à la station de base maîtresse MeNB l’information PHR (Power HeadRoom) concernant à la fois le lien sur la station maitresse et secondaire.
Le terminal transmet également les rapports de puissance régulièrement vers l’entité maitresse MeNB. L’entité MeNB transfert les informations de mesure vers l’entité secondaire SgNB.