(Suite de l’article précédent)
2) La procédure de déclenchement
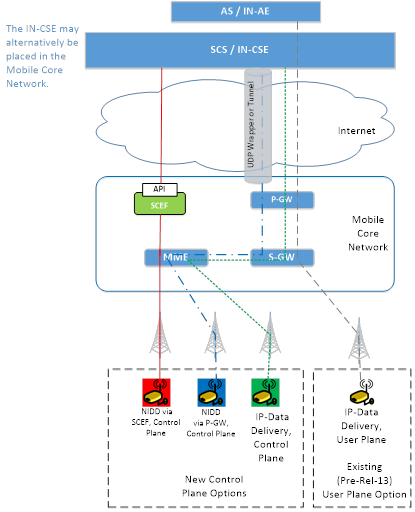
La procédure de déclenchement a été proposée dans la recommandation technique de la release R.10 afin de permettre à un dispositif IoT de répondre à une sollicitation du portail client (SCS). La procédure de déclenchement de dispositif est normalisée dans la release R.11 et nécessite une première phase d’enregistrement de la part du serveur SCS auprès de l’entité SCEF ou MTC-IWF avec comme droit d’émettre des requêtes de réveil (Trigger Request). La phase d’enregistrement a pour but de créer un identifiant de transaction et les droits de requêtes formant ainsi une entrée dans la table de contexte de l’entité MTC-IWF/SCEF à laquelle se rajoute l’identifiant du ou des dispositifs à réveiller. Le dispositif peut s’identifier à partir de son numéro MSISDN, d’un identifiant externe sauvegardé sur le serveur MTC AAA de l’opérateur ou d’un identifiant de groupe.
Dans les spécifications 3GPP de la Release 11, l’entité SCS contacte l’entité MTC-IWF via une requête DIAMETER afin que ce dernier puisse réveiller le dispositif. Lorsque l’entité MTC-IWF reçoit une demande de réveil, il contacte d’abord la base de données HSS (ou le HLR) afin de convertir l’identité publique en une identité interne au réseau opérateur (identifiant IMSI). L’entité HSS/HLR peut éventuellement contacter un serveur d’authentification MTC-AAA pour convertir une identité externe en un numéro IMSI. Si l’identité de l’UE MTC est reconnue, l’entité MTC-IWF récupère les informations de souscription du afin de mettre en relation le portail client SCS avec le dispositif.
L’entité MTC-IWF définit la méthode de réveil la plus adéquate sur le plan de contrôle pour déclencher une mesure au niveau du dispositif à partir des informations suivantes :
- Les informations actuelles d’accessibilités de l’UE (sur quel réseau l’UE est situé, et sur quel zone) ;
- Les méthodes de déclenchement de service supporté par le réseau HPLMN ou VPLMN ;
- Les méthodes de déclenchement supportées par l’UE ;
- Les politiques de déclenchement de réveil de l’opérateur ;
- Autres informations reçues de la part du serveur SCS dont potentiellement la localisation du dispositif si celle-ci est connue. La localisation permet d’optimiser le paging à la cellule et non à la zone de localisation TAI (Tracking Area Identifier).
Les méthodes de réveil possible sont :
- MT SMS. L’UE doit pouvoir reconnaître dans le message un MT SMS provenant du SCS ;
- Cell Broadcast : La procédure Cell Broadcast permet de réveiller un dispositif UE en émettant des informations sur les SIB portés par le canal balise ;
- Signalisation NAS ;
- Messages IMS.
De manière plus explicite, la figure 3 présente le call flow de la procédure de déclenchement. On suppose que le serveur SCS s’est préalablement enregistrée auprès de l’entité MTC-IWF et au cours de la procédure d’enregistrement, le portail client SCS a associé le dispositif UE à réveiller. L’entité SCS connait l’adresse IP de l’entité MTC-IWF, dans le cas contraire, le portail client SCS fait une requête DNS.
La demande de réveil est initialement déclenchée par une API provenant du serveur d’application Client vers l’entité SCS (non présente sur le call-flow). L’entité SCS transmet le message Request Device trigger à l’entité MTC-IWF (éventuellement après une requête DNS) dans la commande DIAMETER DAR (Device Action Request) à travers l’interface Tsp.
Le message DAR contient les informations suivantes (AVP) :
- Le type de message : Device Trigger Request
- Le MSISDN ou une identité externe correspondant à l’UE MTC à réveiller
- L’identité du SCS qui émet la requête.
- Un numéro de référence de la demande de requête de réveil
- Les données de Trigger contenant données à transmettre à l’UE MTC lors de la demande de réveil comme :
- Priorité du trigger
- L’identification du port de l’application à exécuter au niveau du dispositif
- Une durée de validité du message de réveil. Un temporisateur est déclenché au niveau du MTC-IWF qui reçoit le message DAR.

Figure 2. Call Flow d’un réveil de dispositif par SMS
L’entité MTC-IWF peut interdire ou autoriser la requête de réveil à partir de l’identité du serveur SCS si le serveur SCS n’est pas reconnu ou si le serveur SCS a dépassé le nombre de requêtes autorisées.
La durée de validité permettra à l’entité MTC-IWF de savoir si le dispositif sera joignable avant la fin du temporisateur. L’entité MTC-IWF aura besoin de connaitre la durée pendant laquelle le dispositif est soit à l’état dormant, soit en mode de veille avant la prochaine écoute de paging (Paging Occasion). Si le dispositif ne peut pas être réveillé pendant la durée de validité du message de réveil, alors l’entité MTC-IWF retourne un rapport d’erreur dans le message DAA.
L’entité MTC-IWF contacte l’entité HSS (éventuellement après une résolution HSS via la fonction de localisation SLF). A la réception de la requête DIAMETER SIR, l’entité HSS réalise les opérations suivantes :
- Correspondance entre le numéro publique (MSISDN ou identité MTC externe) avec l’identité privée IMSI du dispositif ;
- Récupère -si le dispositif est enregistré- le nœud de service actuel du dispositif (soit l’entité MME, l’entité SGSN, ou l’entité MSC) ;
- Vérifie les droits de souscriptions du dispositif en correspondance avec l’identification du serveur SCS pour valider ou non la requête de réveil.
L’entité HSS répond à l’entité MTC-IWF par la requête SIA avec les éléments suivants :
- Le nœud de service (MSC, SGSN, SGW) actuel du dispositif ;
- Renvoie le statut du dispositif (UE State Information) permettant de savoir si le dispositif est à l’état connecté, de veille, ou non enregistré (absent). Cette information est apportée par le HSS ;
- Le ou les mécanismes supportés par le dispositif (information apportée par le HSS) ;
- Les capacités de services offertes par le réseau de l’opérateur Home (framework implémenté dans le MTC-IWF) et éventuellement par l’opérateur visité en cas de roaming ;
- Autres informations transmises par le SCS (localisation du dispositif, demande de réveil groupé, …).
A partir des informations reçues, l’entité MTC-IWF sélectionne le mécanisme pour transmettre la requête de réveil au dispositif le plus efficace (SMS, Cell Broadcast, …) et génère un ticket de taxation.
L’entité MTC-IWF sélectionne la méthode SMS pour réveiller le dispositif. Il émet au serveur SMC-SC (SMS Service Center) la requête DTR.
Le message DTR contient :
- le numéro IMSI du dispositif et éventuellement le MSISDN si le MTC-IWF le connait (si le SCS a donné l’identité MSISDN au MTC-IWF et non un identifiant MTC externe) ;
- l’identité de l’entité SCS ;
- l’identité du nœud de service (SGSN, MSC ou MME) si connu ;
- le statut du dispositif ;
- le numéro de référence de la demande de requête de réveil ;
- la durée de validité du message de réveil ;
- la Priorité du trigger ;
- l’identification du port d’application du SMS.
Une fois le message DTR reçu, si le dispositif est joignable le centre de service SMS (SMS-SC) n’a pas besoin de contacter l’entité HSS. Il doit néanmoins :
- vérifier l’identité du dispositif (IMSI ou MSISDN). Si l’UE n’est pas reconnu (DIAMETER_ERROR_USER_UNKNOWN) ;
- vérifier l’identité du SCS. Si l’identité du SCS n’est pas reconnu (DIAMETER_ERROR_INVALID_SME_ADDRESS) ;
- Router l’information vers le nœud de service (SGSN, MSC ou MME). Il renvoie alors l’information DIAMETER_SUCCESS à l’entité MTC-IWF.
Si le dispositif est non enregistré (absent), le centre SMS-SC va stocker le message et envoyer une notification à l’entité HSS (SM Message Delivery Status Report) afin que l’entité HSS rajoute l’adresse du centre SMS-SC dans la liste des messages d’attentes. Ainsi, lorsque le terminal MTC UE fera une demande d’attachement, il prendra connaissance du trigger.
Le centre SMS-SC renvoi le résultat de la demande DTR dans le message DTA. Le code de résultat AVP indique si la requête est acceptée (SUCCESS) ou refusée (FAILURE) avec le code d’erreur correspondant :
- congestion du SMS-SC ;
- adresse SME non valide ;
- erreur de protocole SM.
A ce stade, l’entité MCT-IWF acquitte le message DAR par la réponse DAA, ce qui confirme que la demande de réveil a bien été transmise au SMS-SC.
Le message DAA contient :
- le numéro de référence de la demande de requête de réveil ;
- l’état du statut de la requête de réveil.
Si la requête est acceptée, le centre SMS-SC envoie le SMS vers le MTC UE et attend la notification de SMS. Cette notification est transférée du SMS-SC vers l’entité MTC-IWF dans le message DIAMETER DRR (Delivery Report Request) et l’entité MTC-IWF répondra au SMS-SC par la réponse DRA (Delivery Report Answer).
Le message DRR transmet le rapport de succès ou d’échec de transfert su Trigger par SMS, il contient les informations suivantes :
- l’identité IMSI de l’UE et éventuellement le MSISDN ;
- l’identité du SCS ;
- le résultat de la requête :
- Client Absent
- Mémoire de l’UE remplie
- Transfert réussi.
L’entité MTC IWF informe l’entité SCS de la réception du SMS de la part de l’UE. L’entité MTC-IWF envoie le message DIAMETER DNR (Device Notification Request) au serveur SCS et attend la réponse DNA (Device Notification Accept)
Le DNR contient les informations suivantes :
- le MSISDN ou l’identité externe du dispositif ;
- l’identité du SCS qui a fait la demande de réveil ;
- le numéro de référence de la demande de requête de réveil ;
- la réponse à la demande de réveil.
L’entité SCS acquitte la réception de cette requête en répondant par le message DIAMETER DNA.
Enfin, l’entité MTC-IWF répond à la requête DRR émis par le SMS-SC par la réponse DRA, informant ainsi le SMS-SC d’un succès ou d’une erreur sur l’interface T4.