I) Rappel de l’approche SDN/NFV
Les réseaux traditionnels ont été conçus à partir d’équipements dédiés à une fonction réseau (routeurs, commutateurs, pare-feu, équilibrage de charge, accélérateur WAN, …). Ces équipements sont présents dans le réseau mobile afin d’interconnecter les entités du cœur réseau (EPC) comme le MME, le SGW et le PGW. Chaque équipement est programmé selon une interface logicielle définie par l’équipementier. Le réseau de bout en bout nécessite le déploiement d’un ensemble d’équipements réseaux hétérogènes programmés selon une architecture réseau figée. La modification de cette architecture (nécessaire par exemple pour augmenter la bande passante par l’ajout de nouveaux équipements ou par l’agrégation de lien, …) nécessite un investissement humain important et un investissement matériel
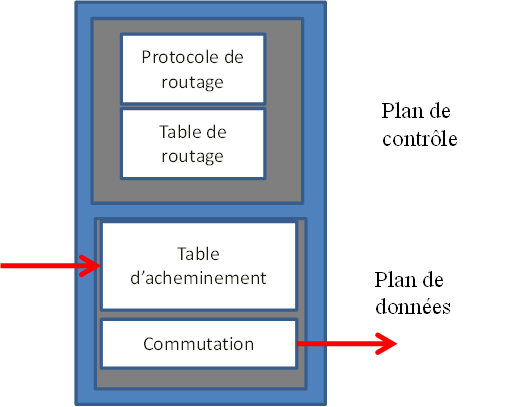
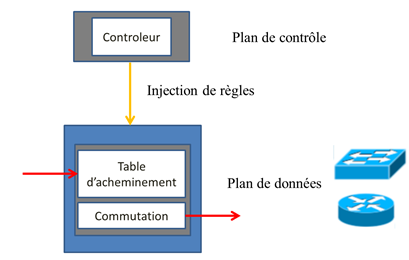
Dans le précédent article, nous avons présenté l’approche SDN qui permet d’augmenter la flexibilité et la disponibilité du réseau et d’accélérer le déploiement de nouvelles applications. Le SDN se définit comme une approche consistant à séparer le plan de contrôle du plan de données. Le plan de contrôle est géré par un équipement nommé contrôleur qui a pour but de piloter l’équipement réseau à travers lequel les données sont traitées. Les équipements réseaux constituent le plan de données.
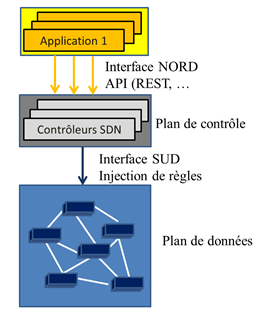
Le premier avantage est de pouvoir exécuter une ou plusieurs règles de réseau sur un équipement standard (nommé COTS signifiant équipement sur l’étagère), autrement dit sans être dépendant de l’évolution logicielle de l’équipementier. Les règles à appliquer sur les flux de données sont fournies par le contrôleur (commutation, VLAN, routage, tag, ..). Lorsque le flux de données doit transiter par plusieurs équipements, il est nécessaire d’activer plusieurs contrôleurs. Les contrôleurs s’échangent des informations sur les interfaces est/ouest afin de piloter l’ensemble du réseau. On parle alors d’orchestration, le pilotage simultané de plusieurs entités réseau du plan de données en vue de gérer le trafic d’un flux de données.
Les contrôleurs ont donc en charge la gestion du réseau c’est à dire l’orchestration et l’automatisation des équipements réseau de différents fournisseurs (chaque fournisseur doit proposer un protocole de signalisation avec le contrôleur comme openflow par exemple).
Le SDN s’associe à une autre technologie, nommée Network Functions Virtualization (NFV). La virtualisation des fonctions réseaux NFV offre la capacité à virtualiser les fonctions du réseau telles que les pare-feu, les mécanismes d’équilibrage de charge et les accélérateurs WAN (cf. note en bas de page). Le contrôle centralisé qu’offre le SDN peut efficacement gérer et orchestrer les fonctions virtuelles qu’offre la NFV ;
Pour résumer, les objectifs du SDN-NFV sont :
- améliorer l’efficacité opérationnelle
- rendre plus flexible le réseau et un ajustement des besoins immédiat
- automatiser la gestion
- permettre le routage dynamique de trafic et le chaînage de fonctions service
- réduire considérablement le temps de mise sur le marché des applications
- provisionnement des fonctions réseaux et création agile de service
- améliorer la satisfaction du client
II L’orientation du trafic (Traffic Steering)
II-1) Les fonctions service
Quand un mobile souhaite accéder au réseau IP, son flux est transmis vers la passerelle PGW ou GGSN. Cette passerelle réalise la fonction de translation d’adresse (NAT) en convertissant l’adresse privée attribuée au mobile en adresse publique et un réacheminement de port (Port Forwarding). L’opérateur peut également déployer un deuxième NAT derrière la passerelle, effectuant ainsi la fonction de Carrier Grade NAT (CGN ou NAT 444).
Cette fonction de NAT est obligatoire, il s’agit de convertir une adresse privée et un port en adresse public et un autre port, l’entité effectuant la translation d’adresse et de port sauvegarde dans une table de correspondance chaque translation privée/publique. Cette fonction service peut être virtualisée et réalisée sur n’importe quel serveur.
Afin de surveiller les flux et bloquer certains type de flux, l’opérateur peut souhaiter activer un service de détection de paquets (DPI : Deep Packet Inspectrion), lequel est associé à un pare-feu (firewall). Enfin, pour équilibrer les flux, il est également possible de rajouter un équilibrage de charge (load balancing), lequel peut orienter le trafic en fonction du port demandé ou du service demandé.
L’opérateur peut imposer, à tous les types de flux, d’être routés à travers ces différentes fonctions service. Les fonctions service classiques sont le NAT, le DPI, le Firewall, et le loadbalancing.
Mohammed Boucadair et David Binet défini [1] :
« Une fonction service (SF, Service Function) désigne une fonction embarquée dans un environnement. Elle peut être co-localisée avec d’autres fonctions service au sein du même équipement, lequel peut être un routeur, un serveur, un commutateur, etc. De telles fonctions SF incluent notamment les fonctions NAT, NAT64, pare-feu IPv4, pare-feu IPv6, TCP Optimizer, NPTv6 »
L’opérateur peut également proposer d’autres fonctions de services comme la détection et l’élimination de malware, le control parental, l’optimisation du cache, une accélération WAN, ou encore un optimisateur de flux vidéos.

Figure 1 :L’orientation statique de trafic
Sur la figure 1, on présente l’exemple ou tous les flux sur le port 80 sont chaînés à toutes les fonctions services d’une plate-forme VAS (Optimisation vidéo, cache, control parental et passerelle WAP) avant d’être acheminés au DPI et au pare-feu.
Dans cet article, on fera régulièrement référence à des fonctions services. Les fonctions services de l’opérateur sont :
- des fonctions de protections du réseau de l’opérateur et des données du client comme le DPI, le pare-feu, les règles d’admissions (ACL), les opérations de chiffrement et déchiffrement, contrôle parental, détection de malware
- des fonctions qui assurent le respect de la qualité d’expérience par des optimisations du trafic (PEP : Performance Enhancement Proxies, optimisation vidéos, optimisation TCP, accélérateur WAN, enrichissement d’entête HTTP…)
- fonction NAPT et CG NAT
II-2) Chaînage de fonctions service statique
Afin d’éviter une surcharge des fonctions réseaux, l’opérateur défini un enchaînement de fonctions service selon le point d’accès APN demandé, c’est-à-dire un ensemble de fonctions service dans un ordre pré-établi.
L’orientation de flux par APN est une orientation dite statique qui s’applique à tous les clients. Il est évidemment possible d’invoquer une orientation de trafic et un enchaînement de fonctions service spécifique par client (gold, silver, bronze) et par application.

Figure 2 : L’orientation du trafic selon l’APN
II-3) Chaînage de fonctions service dynamique
L’opérateur peut choisir d’orienter le trafic en fonction du flux et des droits de l’usager. Pour ce faire, il doit s’appuyer sur un contrôleur centralisé qui analyse les types de flux (modèle hairpin).

Figure 3 : L’orientation de trafic via un controleur (Hairpinning)
Pour atteindre ces objectifs, le contrôleur doit interroger l’entité PCRF pour récupérer le profil et les services avec la QoS associée. Le choix d’orientation de trafic est basé sur la politique des qualités de services par flux (Policy-Based “per-flow” Steering) et le contrôleur effectue un choix selon les informations suivantes (une ou plusieurs informations) :
- Politique de tarification de l’usager (gold, silver, bronze)
- Type de réseau d’accès RAT (2G / 3G / 4G/ Wifi)
- Localisation (roaming)
- Problème de congestion de réseau
- Type de dispositif (IMEI, HTTP User-Agent)
- Type de contenu (HTTP Content-Type, DPI signature) …
Exemple (https://f5.com/portals/1/pdf/events/Traffic-Steering-PEM.pdf) :



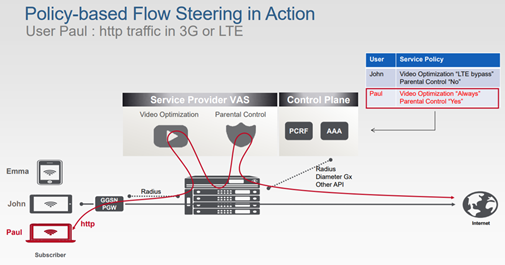
Figure 4 a/b/c/d : Exemple d’orientation de trafic
III Chaînage de fonction services (SFC : Service Function Chaining)
Lors de la construction d’un support (bearer), la sélection de l’entité PGW s’effectue à partir du nom du point d’accès APN. Le chaînage de fonctions service statique, vu précédemment, est donc réalisé en ordonnant les fonctions service en sortie du PGW (cf .figure 2). Cependant, en récupérant des informations du PCRF, la fonction PCEF (située dans le PGW) peut réaliser la fonction d’orientation de trafic (traffic steering).
Le service de chaînage de fonctions service (SFC) est une architecture définit par l’IETF de manière à établir une liste ordonnée de fonctions service réseau.

Figure 5 : L’architecture SFC
Afin de rendre enchaînement de service plus flexible, le chaînage de fonctions service permet de définir une liste ordonnée de services réseaux (pour rappel, pare-feu, équilibrage de charge, optimisation WAN, … ) et d’assembler ces services ensemble pour créer un enchaînement de services. L’architecture proposée par l’IETF est basée sur le principe du SDN. Le contrôleur SFC s’appuie sur une base de données pour connaitre les règles de politiques (table de politique SFC) pouvant être appliquées sur chaque flux et pour chaque abonné.
Pour réaliser cette fonction de chaînage, un classificateur de service (SFC Classifier) est une entité qui classe les flux de trafic en fonction des règles fournies par le contrôleur SFC. Les trames/paquets du flux sont ensuite marqués par un indicateur de chaînage de fonctions service (SFCI Service Function Chain Identifier) à l’intérieure d’une entête NSH (Network Service Header – RFC 8300). Le NSH est un protocole d’encapsulation et l’entête NSH est insérée comme metadata en plus de la data et l’extension d’entête http (http header extension) informe l’existence de la metadata.
En reprenant les définitions proposées dans la référence [1] :
« Un classificateur est une entité qui classe les paquets selon les chaînes SFC auxquels ils sont associés, conformément aux rêgles de classifications définies par le PDP – Policy Decision Point( et stockées dans une table de politique SFC. Les paquets sont ensuite marqués pour identifier la chaîne SFC à laquelle les paquets sont associés »
Il y a ainsi deux approches :
- la première consiste à utiliser le SDN overlay (cf. article portant sur le SDN) et l’entête NSH est encapsulée dans le protocole VXLAN ;
- la seconde approche s’appuie sur les équipements existants dans le réseau mobile, c’est donc celle que nous allons étudier. L’entête NSH est encapsulée dans le protocole GTP-U.
La 3GPP propose dans la release R.11 une nouvelle entité nommée fonction de détection de trafic TDF (Trafic Detection Function). Cette fonction est destinée à analyser les requêtes issues du PGW en faisant de l’inspection de paquet (DPI) et à filtrer uniquement les applications selon des règles de détection d’application (ADC : Application Detection and Control) fournies par le PCRF via une requête Diameter.
La décision sur les règles ADC fournies par le PCRF est basée sur :
- des informations fournies par le PCEF comme par exemple : Type de requête, des informations sur le client ou l’entité UE (IMSI ou IMEI), la localisation ;
- des informations fournies par l’entité SPR tels que des informations sur la QoS pour l’abonnée (débit garanti, AMBR, …)
Le rôle premier de l’entité TDF est d’améliorer les fonctions de tarification de l’opérateur. La fonction TDF est intégrée dans le bloc PCC (Policy and Charging Control). Le TDF a pour rôle d’inspecter le trafic utilisateur à la sortie du PGW et d’assister les outils de taxation sur l’usage du réseau mobile effectué par le client. Ainsi, si pour un accès sur le port 80, l’utilisateur veut lancer une application OTT, via le TDF l’opérateur peut détecter cette application. Une fois l’application détectée, soit la fonction TDF réalise une mesure de la volumétrie consommée pour cette application (dans le sens montant et/ou descendant) spécifiquement, soit la fonction TDF informe l’entité PCRF afin que ce dernier réalise une politique de traitement pour cette application. La politique de traitement correspond à l’un des trois cas suivants :
- Blocage de l’application : Gating;
- Limitation de débit;
- Redirection : Enchainement de fonctions service particulier
L’entité TDF, via l’analyse de la couche application, est en mesure de classifier plus finement le trafic issu du PGW afin de proposer des fonctions réseaux dédiées à chaque application (autrement dit pour appliques des fonctions de service spécifique). L’entité TDF est donc un classificateur de service (SFC Classifier) et le PCRF est vu comme la table de politique de chaînage de fonctions service ( SFC Policy Table).

Figure 6 : L’architecture 3GPP et SFC
Le figure 6 met en avant deux domaines SFC (un domaine SFC est un réseau qui met en oeuvre le chaînage de fonctions service). L’entité TDF est un nœud de bordure sortant (SFC Egress Node) et l’entité IETF SFC Classifier est un nœud de bordure entant (SFC Ingress Node)
La norme 3GPP propose, dans la release R.13, une nouvelle entité TSSF (Traffic Steering Support Function). La fonction TSSF est extraite de l’entité TDF et elle est destinée à la classification du trafic afin de spécifier les fonctions de service à appliquer selon la classification de l’application. Le TSSF met en œuvre l’orientation de trafic sur l’interface Gi (SGi) à partir des règles reçues par le PCRF. La principale différence est l’utilisation du protocole JSON sur l’interface St entre l’entité PCRF et l’entité TSSF qui permet d’échanger les règles de classification de flux plus simplement que l’interface Diameter entre l’entité PCRF et l’entité TDF. L’entité TSSF peut transmettre les métadatas reçus du PCRF sur l’interface Gi LAN.
Selon l’approche SDN, la fonction TSSF est un contrôleur SDN qui injecte ses règles à l’entité TDF.
Dans le prochain article, nous étudierons le chaînage de fonctions service (SFC) avec la virtualisation : Le VNFFG (Virtual Network Function Forwarding Graph).
Merci à Mohamed Boucadair et Christian Jacquenet d’avoir apporté des précisions sur l’article.
A lire :
[1] Mohamed Boucadair, David Binet, « Structuration dynamique de services- Introduction au chaînage de fonctions service (SFC) », Techniques de l’Ingénieur, publié le 10 octobre 2015.
Annexe : Protocoles d’échange entre le PCRF et le TDF sur l’interface Sd