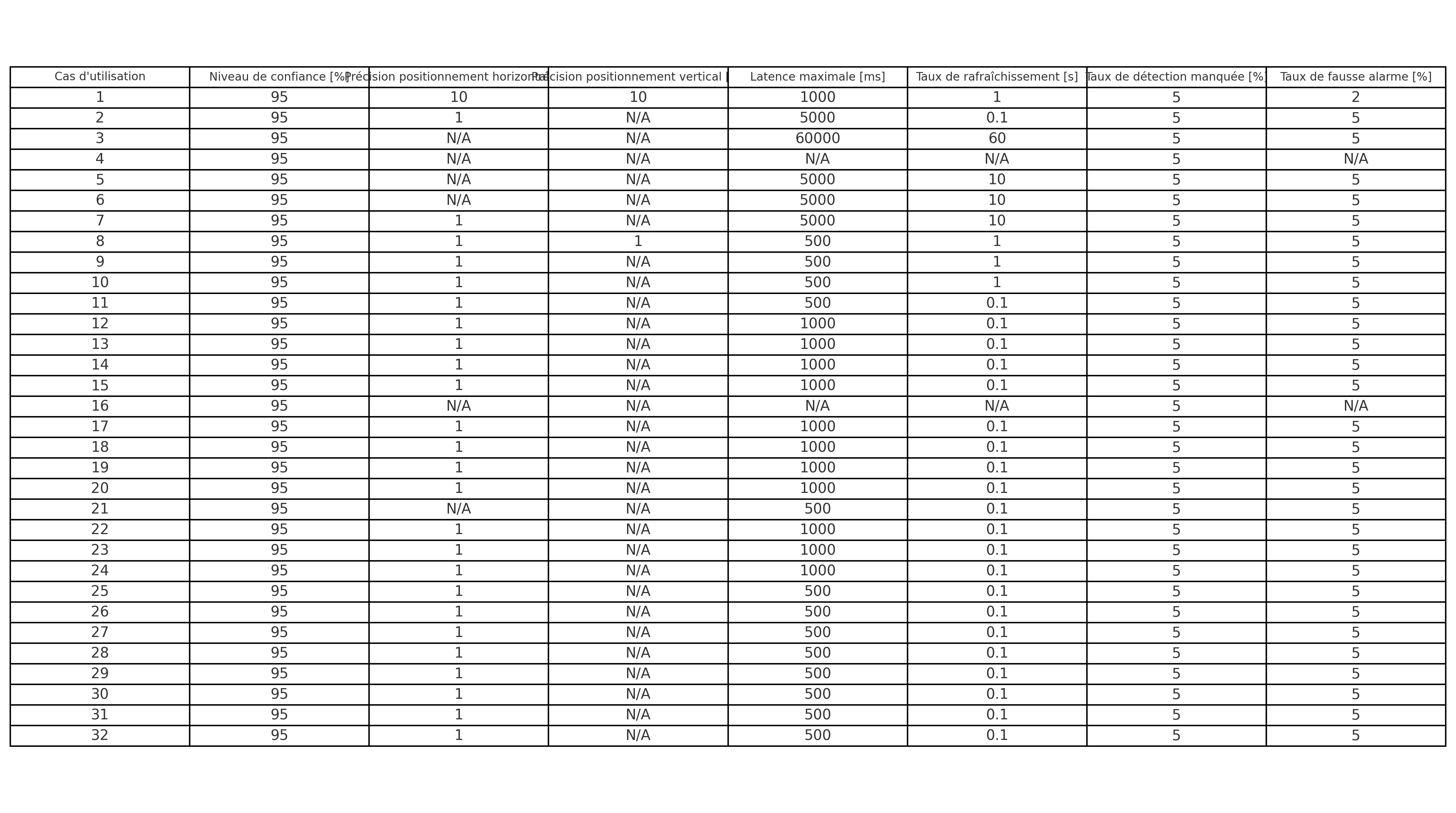
Dans l’article précédent nous avions présenté 3 d’apprentissages IA. Nous allons maintenant revenir plus particulièrement sur l’apprentissage fédéré horizontal (HFL) et vertical (VLF)
Le fonctionnement du HFL et VFL pour l’IA dans les réseaux de télécommunications
Introduction à l’apprentissage fédéré
L’apprentissage fédéré est une approche d’entraînement de modèles d’IA qui permet de développer des modèles à partir de données distribuées sur différents appareils ou serveurs, sans nécessiter le transfert des données brutes vers un serveur central. Cette approche est particulièrement pertinente dans le contexte des télécommunications où la confidentialité des données, la réduction de la bande passante et la distribution géographique sont des considérations importantes.
Deux principales variantes d’apprentissage fédéré sont mentionnées dans le document de 5G Americas et développées dans la littérature scientifique: l’apprentissage fédéré horizontal (HFL) et l’apprentissage fédéré vertical (VFL).
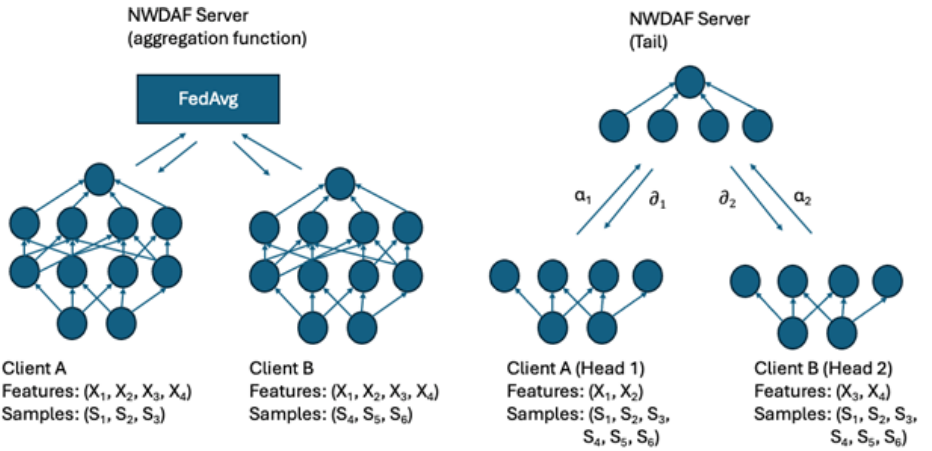
Figure 1 : HFL (gauche) et VFL (droite)
Apprentissage Fédéré Horizontal (HFL)
Principe fondamental
Selon le document, le HFL (souvent simplement appelé « apprentissage fédéré ») est une technique où le modèle d’apprentissage automatique est entraîné sur différents « clients » (nœuds, appareils ou serveurs) qui possèdent des données avec les mêmes caractéristiques mais concernant des échantillons différents.
En termes plus simples, dans le HFL:
- Chaque participant dispose du même type de données (mêmes features/variables)
- Mais chacun a des exemples/échantillons différents (différentes instances)
Fonctionnement détaillé
- Initialisation: Un modèle global initial est créé sur le serveur central (NWDAF serveur dans le contexte des télécommunications).
- Distribution du modèle: Ce modèle est envoyé à plusieurs clients (par exemple, différents NWDAF locaux dans différentes zones géographiques).
- Entraînement local: Chaque client entraîne le modèle sur ses données locales pendant plusieurs itérations.
- Agrégation des paramètres: Les clients renvoient uniquement les paramètres du modèle mis à jour (pas les données) au serveur central.
- Mise à jour du modèle global: Le serveur central agrège ces paramètres (typiquement par une forme de moyenne pondérée) pour créer une version améliorée du modèle global.
- Itération: Les étapes 2-5 sont répétées à travers plusieurs cycles jusqu’à ce que le modèle converge ou atteigne des performances satisfaisantes.
Avantages dans le contexte des télécommunications
- Confidentialité: Les données sensibles restent sur leurs appareils/serveurs d’origine.
- Efficacité de communication: Seuls les paramètres du modèle sont transmis, pas les données brutes, réduisant considérablement la charge du réseau.
- Adaptation locale: Le modèle peut capturer les spécificités locales tout en bénéficiant de l’apprentissage collectif.
Application dans le NWDAF (3GPP)
Dans les réseaux 5G, comme mentionné dans le document, le HFL a été introduit dans la Release 17 du 3GPP pour le NWDAF. Il permet:
- L’entraînement collaboratif entre différentes zones d’intérêt (parties du réseau)
- Chaque zone utilise le NWDAF le plus proche pour entraîner localement
- L’apprentissage collectif est agrégé par une fonction centrale sur le NWDAF serveur
- Des protocoles préservant la confidentialité comme l’agrégation sécurisée peuvent être appliqués
Apprentissage Fédéré Vertical (VFL)
Principe fondamental
Le VFL, introduit dans la Release 19 pour le NWDAF selon le document, est conçu pour des scénarios où différents participants possèdent différentes caractéristiques/features pour les mêmes échantillons (ou un chevauchement significatif des échantillons).
En termes simplifiés, dans le VFL:
- Chaque participant a des types de données différents (features différentes)
- Mais ils concernent le même ensemble d’utilisateurs ou d’entités (mêmes échantillons)
Fonctionnement détaillé
- Division du modèle: Dans le VFL, le modèle d’apprentissage est divisé en « modèle de tête » et « modèle de queue »:
- Les modèles de tête sont déployés chez les participants (par exemple, Client A et Client B)
- Le modèle de queue est hébergé sur un serveur central
- Processus d’entraînement:
- Propagation avant: Les clients traitent leurs données locales à travers leurs modèles de tête
- Transfert d’activations: Les résultats intermédiaires (activations) sont envoyés au serveur central
- Concaténation: Le serveur central concatène ces activations
- Calcul de perte: Le modèle de queue calcule une perte en utilisant les étiquettes disponibles sur le serveur
- Rétropropagation: Les gradients sont calculés et les dérivées partielles correspondantes sont renvoyées aux clients
- Mise à jour locale: Chaque client met à jour son modèle de tête en fonction des gradients reçus
- Alignement des échantillons: Pour que le VFL fonctionne, il est crucial d’aligner les échantillons entre les participants, généralement à l’aide d’identifiants uniques comme des horodatages ou des identifiants d’utilisateur (SUPI dans le contexte 5G).
Avantages spécifiques au VFL
- Enrichissement des caractéristiques : Permet de combiner différentes perspectives ou types de données sans les partager directement
- Architecture personnalisée: Chaque participant peut avoir sa propre architecture de réseau neural
- Complémentarité des données: Permet d’exploiter des données complémentaires détenues par différentes entités
Application dans les réseaux 5G (NWDAF)
Selon le document, dans la Release 19 du 3GPP, le VFL est introduit pour permettre la collaboration entre:
- Les NWDAF dans le réseau cœur
- Les fonctions d’application (AF) qui peuvent détenir d’autres types de données
Cette approche permet notamment:
- La prédiction de QoS en utilisant à la fois des données réseau et des données applicatives
- Une meilleure adaptation aux besoins spécifiques grâce à des architectures de modèle personnalisées
- L’extension des fonctionnalités existantes développées pour le HFL
Différences clés entre HFL et VFL
En synthétisant les informations du document et la littérature sur le sujet:
| Aspect | HFL (Horizontal) | VFL (Vertical) |
|---|---|---|
| Partitionnement des données | Même espace de features, échantillons différents | Features différentes, mêmes échantillons |
| Architecture du modèle | Modèles identiques sur tous les clients | Division tête/queue avec architectures potentiellement différentes |
| Communication | Paramètres du modèle complet | Activations et gradients partiels |
| Confidentialité | Protège la confidentialité des échantillons | Protège la confidentialité des features |
| Cas d’usage typique dans 5G | Apprentissage entre différentes zones géographiques | Collaboration entre réseau cœur et applications |
| Complexité d’implémentation | Plus simple (agrégation directe des modèles) | Plus complexe (coordination entre sous-modèles) |
Protection de la confidentialité dans HFL et VFL
Les deux approches intègrent des mécanismes pour renforcer la confidentialité:
Dans le HFL:
- Agrégation sécurisée: Techniques cryptographiques pour agréger les mises à jour de modèle sans révéler les contributions individuelles
- Distillation de connaissances: Transfert de connaissances sans partager les paramètres exacts du modèle
- Quantification et élagage: Réduction de la précision ou de la taille des modèles pour limiter les fuites d’information
Dans le VFL:
- Calcul multi-parties: Techniques permettant des calculs conjoints sans partager les données sous-jacentes
- Chiffrement homomorphe: Opérations sur des données chiffrées sans les déchiffrer
- Perturbation différentielle: Ajout de bruit aux activations partagées pour protéger la confidentialité
Implémentation dans un réseau de télécommunications
Dans le contexte spécifique des réseaux de télécommunications, le document de 5G Americas décrit l’implémentation de ces approches:
Pour le HFL:
- Déployé entre différentes zones géographiques du réseau
- Les NWDAF clients sont situés près des zones qu’ils desservent
- Un NWDAF serveur central coordonne l’agrégation
- Les modèles peuvent prédire des comportements comme la charge du réseau ou la mobilité des utilisateurs
Pour le VFL:
- Permet la collaboration entre le réseau cœur et les applications externes
- Les prédictions peuvent combiner des données réseau (comme les conditions du signal) avec des données applicatives (comme les exigences des applications)
- Permet de préserver la séparation entre domaines administratifs tout en bénéficiant du partage de connaissances
Conclusion: évolution et tendances futures
L’évolution de l’apprentissage fédéré dans les réseaux de télécommunications, comme le montre le document 5G Americas, suit une progression naturelle:
- D’abord introduction du HFL dans la Release 17, permettant la collaboration entre différentes parties du réseau
- Extension au transfert de modèles entre domaines administratifs dans la Release 18
- Introduction du VFL dans la Release 19, permettant la collaboration entre le réseau et les applications
Cette évolution reflète une tendance plus large vers:
- Des réseaux de plus en plus intelligents et adaptatifs
- Une intégration plus profonde entre les réseaux et les applications qu’ils supportent
- Une attention croissante à la confidentialité et à l’efficacité des communications
Le HFL et le VFL représentent deux approches complémentaires d’apprentissage fédéré qui, ensemble, permettent une collaboration plus riche et plus flexible entre les différentes entités d’un écosystème de télécommunications, tout en respectant les contraintes de confidentialité et d’efficacité.