Comment fonctionne le modèle ? ML/IA : Principes fondamentaux et cycle de vie des modèles
I) Introduction
L’intelligence artificielle (IA) et l’apprentissage automatique (machine learning ou ML) transforment notre façon d’aborder les problèmes complexes dans de nombreux domaines. Ce document explique les principes de base du fonctionnement de ces technologies et détaille leur cycle de vie, de la conception à l’exploitation.
Le cycle de vie est défini dans le document TR28.105 et sera réexpliqué dans un autre article.
Des cas d’usages sont proposés dans le document TR28.908 et seront listés dans un autre article.
L’objectif de l’IA est de pouvoir répondre au plus juste à la question posée. A chaque question, on évalue la réponse. Cela suppose donc une phase d’apprentissage et une une phase d’examen. Les phases d’apprentissage et d’inférence sont, par analogie, comme étudier pour un examen (entraînement) puis passer l’examen réel (inférence).
L’inférence traduit simplement la réponse de l’IA à de nouvelles situations en appliquant ce qu’elle a appris.
Dans le monde réel, l’inférence, c’est quand votre téléphone reconnaît votre visage, quand un assistant vocal comprend vos paroles, ou quand une application de traduction convertit un texte d’une langue à une autre. Le système utilise ce qu’il a appris pendant l’entraînement pour traiter la nouvelle entrée que vous lui donnez.
Dans le cas des réseaux mobiles, l’IA est un assistant pour détecter des pannes. Il doit donc faire une analyse, récupérer des rapports, mais surtout réaliser des actions. Les actions peuvent être rédiger un tocketing vers un prestataire (supposons que la station de base défaillante est sur un TELCO d’un autre opérateur), ou un ticketing vers une équipe spécialisée. L’IA doit ensuite suivre l’intervention de bout en bout.
A ce jour, je liste que deux solutions IA intéressantes pour automatiser (détecter, analyser et réaliser une/des actions) qui sont :
Je parlerais des ces deux IA dans un autre articles.
II)Comprendre le ML et l’IA
L’intelligence artificielle désigne les systèmes capables d’accomplir des tâches qui nécessiteraient normalement l’intelligence humaine. Le machine learning est une sous-discipline de l’IA qui permet aux systèmes d’apprendre à partir de données sans être explicitement programmés pour chaque tâche.
Principes fondamentaux
Le ML repose sur trois approches principales :
- Apprentissage supervisé : le modèle apprend à partir d’exemples étiquetés (données d’entrée associées aux sorties attendues).
- Apprentissage non supervisé : le modèle découvre des structures ou des motifs cachés dans des données non étiquetées.
- Apprentissage par renforcement : le modèle apprend par essais et erreurs, recevant des récompenses ou des pénalités selon ses actions.
Comment les modèles « apprennent »
Au cœur du ML se trouve le concept de modèle : une représentation mathématique qui transforme des entrées en sorties. L’apprentissage consiste à ajuster les paramètres de ce modèle pour minimiser l’erreur entre ses prédictions et les résultats attendus.
Ce processus s’appuie sur :
- Des données représentatives du problème
- Des algorithmes qui déterminent comment ajuster les paramètres.
- Des fonctions d’objectif qui mesurent la performance
- Des techniques d’optimisation pour améliorer progressivement les résultats.
L’entrainement peut être sur un serveur centralisé ou sur des serveurs distribués. On parle alors d‘apprentissage fédéré.
L’apprentissage fédéré est une approche distribuée où le modèle est entraîné sur plusieurs appareils ou serveurs sans échanger les données brutes.
L’apprentissage fédéré est une décentralisation des données et permet la protection de la vie privée, quelle que soit la méthode d’apprentissage utilisée (supervisée ou non supervisée).
Le cycle de vie d’un modèle ML/IA
Un modèle d’IA/ML suit généralement un cycle de vie structuré, composé des étapes suivantes :
- Entraînement du modèle ML
L’entraînement constitue la phase où le modèle « apprend » à partir des données. Cette étape comprend :
• L’entraînement initial : exposition du modèle aux données d’entraînement pour qu’il ajuste ses paramètres.
• La validation continue : évaluation des performances du modèle sur des données de validation distinctes.
• Le réentraînement : ajustement du modèle si les résultats de validation ne sont pas satisfaisants
L’objectif est d’obtenir un modèle qui capture efficacement les relations dans les données tout en évitant le surapprentissage (mémorisation des données d’entraînement sans capacité de généralisation).
- Test du modèle ML
Une fois le modèle validé, il est soumis à une phase de test rigoureuse :
• Le modèle est évalué sur un ensemble de données de test totalement nouvelles.
• Les performances sont mesurées selon des métriques spécifiques au problème (précision, rappel, F1-score, etc.).
• Si les performances ne répondent pas aux attentes, un retour à l’étape d’entraînement est nécessaire.
Cette étape est cruciale pour déterminer si le modèle est capable de généraliser ses apprentissages à des données inédites.
- Émulation d’inférence AI/ML (optionnelle)
Avant le déploiement en environnement réel, le modèle peut être testé dans un environnement d’émulation pour :
• Évaluer les performances d’inférence (vitesse, latence, ressources consommées)
• Vérifier la compatibilité avec l’infrastructure cible.
• Identifier les potentiels impacts négatifs sur d’autres systèmes
Cette étape, bien qu’optionnelle, permet d’anticiper les problèmes techniques qui pourraient survenir en production.
- Déploiement du modèle ML
le déploiement consiste à rendre le modèle opérationnel dans son environnement cible :
• Processus de chargement du modèle dans l’infrastructure d’inférence
• Intégration avec les systèmes existants
• Configuration des paramètres d’exécution
Dans certains cas, cette étape peut être simplifiée, notamment lorsque les environnements d’entraînement et d’inférence sont co-localisés.
- Inférence AI/ML
L’inférence représente l’utilisation effective du modèle en production.
• Le modèle traite les nouvelles données entrantes et génère des prédictions.
• Un système de surveillance évalue continuellement les performances.
• Des mécanismes peuvent déclencher automatiquement un réentraînement si les performances se dégradent.
Cette phase correspond à la « vie active » du modèle, où il crée de la valeur en résolvant les problèmes pour lesquels il a été conçu.
Considérations pratiques et avancées
Maintenir un système d’IA/ML en production performant implique de relever plusieurs défis :
1. Dérive des données : les caractéristiques des données réelles évoluent avec le temps, rendant progressivement le modèle moins précis.
2. Besoins computationnels : L’entraînement et l’inférence peuvent nécessiter d’importantes ressources de calcul, particulièrement pour les modèles complexes.
3. Explicabilité : comprendre pourquoi un modèle a pris une décision particulière devient crucial dans de nombreux contextes réglementaires.
4. Biais et équité : les modèles peuvent perpétuer ou amplifier les biais présents dans les données d’entraînement.
Pour maximiser les chances de succès d’un projet ML/IA :
- Surveillance continue : mettre en place des mécanismes pour détecter les dégradations de performance
- Réentraînement périodique : actualiser régulièrement le modèle avec des données récentes.
- Tests A/B : comparer les performances de différentes versions du modèle
- Documentation exhaustive : Maintenir une traçabilité complète du développement et des choix effectués
L’évolution du domaine ML/IA se caractérise par plusieurs tendances :
- MLOps : automatisation et standardisation des processus de déploiement et de maintenance des modèles
- Apprentissage fédéré : entraînement distribué préservant la confidentialité des données
- Modèles auto-supervisés : réduction de la dépendance aux données étiquetées
- ML embarqué : exécution de modèles directement sur des appareils en périphérie (edge computing)
MLOps et DevOps
MLOps est un ensemble de pratiques visant à automatiser et rationaliser le cycle de vie des modèles d’IA de leur déploiement à leur production et opération:
Surveillance et gestion de la performance
- Surveillance en temps réel: Surveillance continue de la performance des modèles d’IA en production pour assurer qu’ils opèrent comme prévu, impliquant le suivi de métriques comme la précision, la latence et l’utilisation des ressources.
- Boucles de feedback: Implémentation de boucles de feedback pour collecter des données de performance et le feedback utilisateur, qui peuvent être utilisés pour affiner et améliorer les modèles d’IA au fil du temps.
Automatisation
- Réentraînement du modèle: Automatisation du processus de réentraînement pour incorporer de nouvelles données et s’adapter aux conditions changeantes, assurant que les modèles d’IA restent pertinents et efficaces à mesure que les environnements réseau évoluent.
- Mise à l’échelle: Utilisation de la mise à l’échelle automatisée pour ajuster les ressources de calcul basées sur les demandes des tâches d’inférence et d’entraînement du modèle d’IA.
- Pipelines CI/CD: Implémentation de pipelines CI/CD pour l’intégration continue et le déploiement des modèles d’IA, incluant l’automatisation du processus de mise à jour des modèles avec de nouvelles données, testant leur performance et les déployant dans des environnements de production.
Pratiques DevOps
Les pratiques DevOps sont essentielles pour intégrer les modèles d’IA dans le cadre plus large de gestion et d’opérations réseau:
- Collaboration et intégration:
- Équipes interfonctionnelles: Promouvoir la collaboration entre les data scientists, les ingénieurs réseau et les équipes opérationnelles pour assurer que les modèles d’IA sont efficacement intégrés dans les opérations réseau.
- Flux de travail unifiés: Développer des flux de travail unifiés qui combinent la gestion réseau et les opérations du modèle d’IA, permettant une intégration et une coordination transparentes entre différents aspects de la gestion réseau.
- Infrastructure as Code (IaC):
- Gestion d’infrastructure automatisée: Utiliser IaC pour automatiser le provisionnement et la gestion de l’infrastructure requise pour l’entraînement et le déploiement du modèle d’IA, incluant la définition et la gestion des ressources réseau à travers le code pour assurer cohérence et efficacité.
- Surveillance et journalisation:
- Journalisation complète: Implémenter des pratiques de journalisation complètes pour suivre la performance du modèle d’IA et les métriques opérationnelles, aidant à identifier les problèmes, déboguer les problèmes et assurer que les modèles répondent aux standards de performance.
Conclusion
Le ML et l’IA représentent des technologies puissantes dont l’efficacité dépend largement de la rigueur avec laquelle leur cycle de vie est géré. De l’entraînement à l’inférence, chaque étape présente des défis spécifiques et requiert une attention particulière.
La compréhension de ce cycle de vie est essentielle pour toute organisation souhaitant tirer profit de ces technologies de manière durable et responsable. Les systèmes ML/IA ne sont pas statiques : ils nécessitent une maintenance et une amélioration continues pour rester performants face à l’évolution constante des données et des besoins.

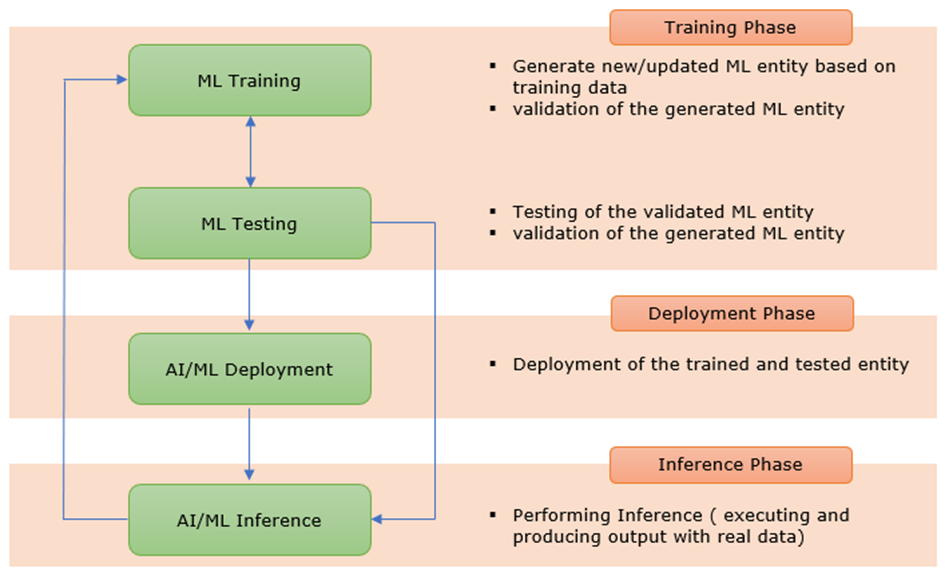 Figure 1 : extraite de Sharetechnote https://www.sharetechnote.com/html/5G/5G_AI_ML.html
Figure 1 : extraite de Sharetechnote https://www.sharetechnote.com/html/5G/5G_AI_ML.html