
L’apport de l’IA sur la couche L1
Introduction
Le RAN est un système complexe nécessitant la configuration précise de centaines de paramètres. L’optimisation manuelle était historiquement laborieuse et coûteuse surtout en 2G avec l’ingénierie cellulaire.
Les réseaux auto-organisés (SON – Self Optimized Networks) ont émergé pour automatiser la planification, la configuration et l’optimisation. Les premiers SON utilisaient des approches heuristiques avec des règles prédéfinies. Mais ces méthodes sont limitées face à la complexité croissante des réseaux modernes.
L’IA/ML offre une opportunité de dépasser ces limitations grâce à l’apprentissage dynamique. L’architecture 6G sera Native-IA.
L’AI native est définie [2] comme « le concept d’avoir des capacités d’IA intrinsèquement fiables, où l’IA est une partie naturelle de la fonctionnalité, en termes de conception, déploiement, opération et maintenance ».
Une implémentation AI native s’appuie sur un écosystème basé sur les données et la connaissance, où les données et connaissances sont consommées et produites pour réaliser de nouvelles fonctionnalités basées sur l’IA ou pour remplacer des mécanismes statiques basés sur des règles par une IA adaptative et apprenante selon les besoins.
II) IA Native
L’architecture AI native comporte quatre aspects principaux:
1. Intelligence partout (Intelligence everywhere)
- L’IA doit pouvoir être exécutée partout où cela a du sens selon une analyse coût-bénéfice
- Cela inclut tous les domaines du réseau, toutes les couches de la pile, tous les sites physiques (du central à la périphérie), et potentiellement même sur les appareils mobiles
- Des environnements d’exécution IA doivent être disponibles partout, et des environnements d’entraînement peuvent être co-localisés si nécessaire.
2. Infrastructure de données distribuée
- L’exécution et l’entraînement des modèles d’IA nécessitent que les données et ressources de calcul (comme les GPU) soient disponibles partout
- Les données disponibles partout permettent aux modèles de s’étendre au-delà des frontières actuelles des couches et domaines
- L’infrastructure doit gérer les contraintes temporelles des données (date de péremption, contraintes légales, volume)
- Les infrastructures de données et les orchestrateurs de modèles doivent interagir: parfois les données sont transportées vers l’intelligence, et parfois l’intelligence doit être rapprochée des données
3. Zero-touch
- La gestion de l’intelligence et de l’infrastructure de données doit être automatisée
- Plutôt que d’introduire de nouvelles opérations manuelles ou automatisées, l’objectif est d’atteindre des opérations entièrement autonomes
- Les humains restent en contrôle en exprimant des exigences au système et en supervisant leur réalisation, mais sans dicter les actions spécifiques à prendre
- Cette approche permet un réseau autonome avec des capacités d’auto-configuration, auto-guérison, auto-optimisation et auto-protection
4. IA en tant que service (AIaaS)
- Les fonctions liées à l’IA et à la gestion des données peuvent être exposées comme services à des parties externes
- Exemples: gestion du cycle de vie des modèles d’IA (entraînement, environnement d’exécution) ou aspects de manipulation des données (exposition de données)
- Cette exposition transforme le réseau en plateforme d’innovation
- Les utilisateurs de ces services peuvent être le fournisseur de services lui-même ou ses clients
Structure de l’architecture AI native
L’architecture AI native peut être représentée comme un système où l’intelligence et l’infrastructure de données traversent toutes les couches traditionnelles du réseau:
- Applications
- Gestion, Orchestration, Monétisation
- Accès, Mobilité, Applications réseau
- Infrastructure cloud
- Transport
III) IA sur la couche Physique
Les applications clés sont décrites sur la figure 1 [1] : gestion des non-linéarités des émetteurs/récepteurs, adaptation de liaison, estimation de canal (CSF : Channal State Feedback).
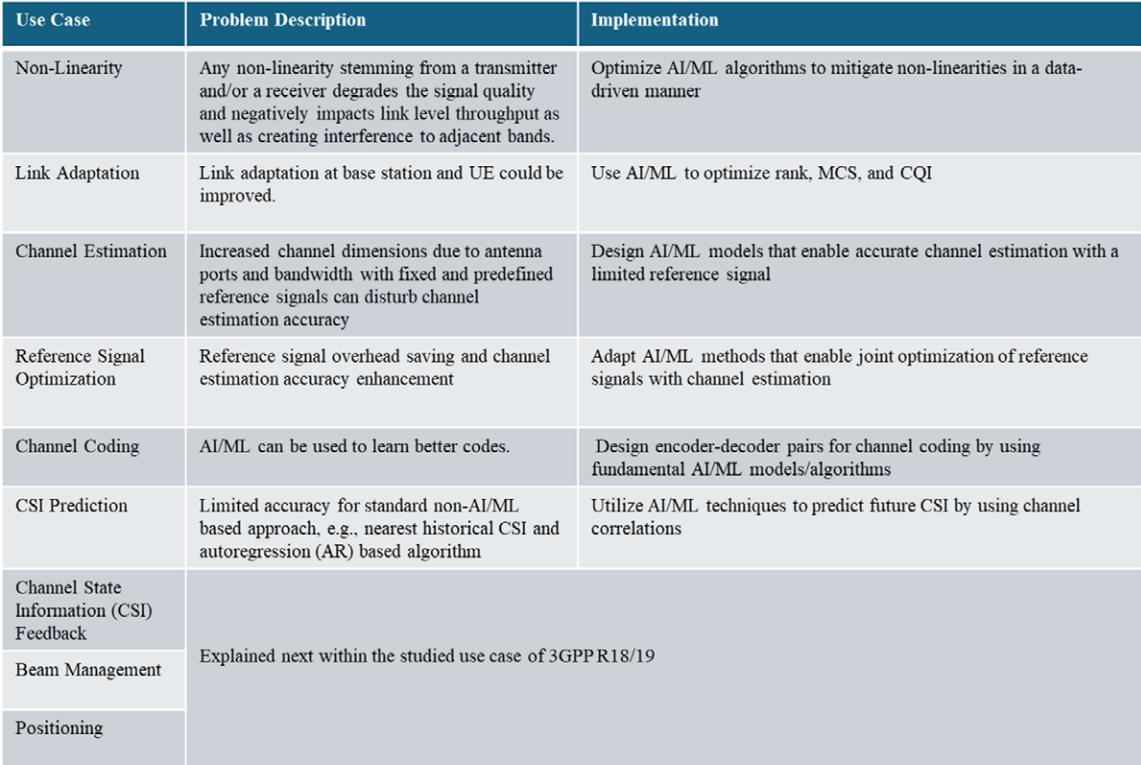 Figure 1 : Cas d’usage de l’IA sur la couche physique RAN [1]
Figure 1 : Cas d’usage de l’IA sur la couche physique RAN [1]
Introduction à l’IA dans la couche physique
Les applications de l’IA dans la couche physique se concentrent principalement sur:
- La gestion des non-linéarités des émetteurs et récepteurs
- L’amélioration de l’adaptation de liaison au niveau de la station de base et des équipements utilisateurs
- L’optimisation de l’estimation de canal et des signaux de référence
- L’exploration du codage de canal piloté par l’IA
Les travaux des groupes 3GPP dans les Release 18 et 19 ont également exploré la prédiction de canal, la compression pour des retours d’information plus efficaces, et les avancées dans la gestion de faisceau et le positionnement.
Le retour d’information sur l’état du canal (CSF) amélioré par l’IA
Importance et défis du CSI
La technologie TDD (Time Division Duplex) permet d’obtenir, dans le cas d’un canal quasi-stationnaire, une réciprocité parfaite entre la liaison montante et la liaison descendante. Ainsi la connaissnce du canal, via le CSI de la liaison descendante est disponible à la station de base à partir de la mesure du signal de sondage en liaison montante. Cependant, dans un système FDD (Frequency Division Duplex) ou un système TDD avec réciprocité non idéale, le CSI de la liaison descendante est acquis par rapport de l’UE.
Dans ce cas, les défis principaux incluent:
- La dimensionnalité élevée du CSI dans les systèmes MIMO massifs à large bande (le nombre de CSI étant de 32 du R.15 au R.18 et 128 à partir de la R.19).
- La surcharge associée à l’acquisition du CSI réduit les ressources radio disponibles
- Les contraintes liées aux périodes de cohérence de canal limitées
Approches traditionnelles et leurs limites
A partir de la 4G, l’utilisation de mots de codes( codebooks CSI) permet de comprimer le CSI à remonter (dans le domaine spatial MIMO et fréquentiel CA). Le nombre d’informations étant élevée, cela nécéssite :
- Demandes élevées de bande passante en liaison montante
- Précision réduite dans la reconstruction de canal à la station de base
- Structure CSI prédéfinie qui manque d’adaptabilité
Solutions basées sur l’IA/ML
L’IA/ML offre une approche pilotée par les données qui détermine dynamiquement le contenu du message de retour d’information. Cette approche est avantageuse car:
- Les modèles IA/ML sont entraînés sur des réalisations de canal réelles
- Ils peuvent s’adapter à différents scénarios
- Ils permettent une compression plus efficace
- Ils améliorent l’équilibre entre surcharge de feedback et précision de reconstruction
Un modèle IA/ML à deux faces pour le retour CSI est proposé pour réduire la charge des informations :
- L’encodeur basé sur un réseau neuronal au niveau de l’émetteur (UE) compresse et quantifie les caractéristiques du canal
- Le décodeur basé sur un réseau neuronal au niveau du récepteur (station de base) reconstruit les caractéristiques du canal
- La paire encodeur-décodeur est entraînée ensemble pour une optimisation de bout en bout
Travaux 3GPP et jalons importants pour le CSF
Les cadres à l’étude pour l’amélioration du retour CSI par l’IA incluent:
- Des modèles à face unique pour la prédiction CSI
- Des modèles à deux faces pour la compression CSI
Le groupe de travail 3GPP RAN1 a étudié l’évaluation de la compression en fréquence et spatiale dans la Release 18, puis a exploré des sous-cas d’utilisation avec compression temporelle dans la Release 19. Des évaluations approfondies ont été menées sur la généralisation à divers scénarios, l’évolutivité à diverses configurations, et les aspects de collaboration multi-fournisseurs.
Pour les modèles à deux faces, diverses architectures ont été envisagées, comme les réseaux de neurones convolutifs (CNN), les mémoires à court et long terme (LSTM), et les transformers. Les approches d’entraînement incluent:
- L’entraînement conjoint du modèle à deux faces d’un seul côté
- L’entraînement conjoint du modèle à deux faces du côté réseau et du côté UE respectivement
- L’entraînement séparé du côté réseau et du côté UE
Un défi majeur dans le déploiement du modèle à deux faces est la complexité de la collaboration inter-fournisseurs.
Des modèles hyper-locaux ont également été étudiés pour exploiter la cohérence spatiale, permettant une meilleure compression des échantillons de canal collectés dans une région locale par rapport aux données globales.
La gestion de faisceau (BM) améliorée par l’IA
Importance et défis du MIMO massif
Si le MIMO massif est une technique clé dans les systèmes 5G, elle utilise d’un nombre élevé de réseaux d’antennes pour réaliser des gains de formation dans une direction donnée. La gestion de faisceau est cruciale pour établir et maintenir la connexion entre la station de base et l’UE dans des conditions de canal dynamiques.
Les défis principaux incluent:
- Inefficacité du protocole de balayage de faisceau, particulièrement pour les bandes de fréquences plus élevées
- Surcharge de messagerie
- Codebooks sous-optimaux avec une approche « taille unique »
- Nouveaux cas d’utilisation nécessitant des performances ciblées sous conditions de mobilité
Solutions basées sur l’IA/ML
Face aux défis des cadres de gestion de faisceau avec recherche exhaustive, les techniques d’IA/ML sont explorées pour:
- Réduire le temps de réponse et la charge de calcul
- Améliorer la sélection de faisceau basée sur des informations contextuelles
- Optimiser la performance réseau sous différentes conditions
Les solutions de gestion de faisceau basées sur l’IA/ML se répartissent principalement en:
- Apprentissage supervisé: utilisant des relations préétablies entre entrées et sorties pour prédire les meilleurs faisceaux
- Apprentissage par renforcement: déployant un apprentissage par essai-erreur et basé sur les récompenses sans nécessiter de connaissances préalables des canaux
Travaux 3GPP et standardisation
L’interface air IA-native supportant des algorithmes IA/ML pour la gestion de faisceau a été étudiée dans la Rel-18 et spécifiée dans la Rel-19. Les objectifs incluent:
- Réduire la consommation d’énergie de l’UE en mesurant moins
- Améliorer l’efficacité énergétique du réseau en transmettant moins de signaux de référence
La prédiction de faisceau s’effectue dans les domaines spatial et/ou temporel, avec des prédictions côté UE et côté réseau. Pour la prédiction temporelle de faisceau, les mesures de puissance des signaux de référence (RSRP) passées sont utilisées pour prédire les meilleurs faisceaux à des instances futures, améliorant ainsi la performance sous conditions de mobilité.
Le document discute également de la généralisation des modèles IA/ML à travers différents scénarios et de la surveillance des performances des modèles pendant l’inférence.
Le positionnement amélioré par l’IA
Importance et limitations des méthodes traditionnelles
Le positionnement est présenté comme un facilitateur clé pour diverses applications, notamment la sécurité, la conduite autonome et l’IoT industriel. Les signaux sans fil peuvent être échangés entre un UE et des points de transmission et de réception (TRP) pour estimer la distance et/ou l’angle en ligne de vue (LOS).
Les méthodes de positionnement 5G NR standard incluent:
- Différence de temps d’arrivée en liaison descendante/montante (TDoA)
- Méthodes basées sur l’angle comme l’angle de départ en liaison descendante (AoD)
- Angle d’arrivée en liaison montante (AoA)
- Temps d’aller-retour multiple
Ces méthodes supposent une condition LOS entre l’UE et le TRP, ce qui peut conduire à des erreurs lorsque l’UE est en condition de non-ligne de vue (NLOS).
Solutions basées sur l’IA/ML
L’IA/ML est présentée comme une solution pour améliorer la précision du positionnement en conditions NLOS en:
- Analysant les chemins de propagation de l’environnement sans fil
- Apprenant leur correspondance avec les informations de localisation
- Créant un modèle qui fait correspondre les mesures de canal dans le domaine temporel à la localisation de l’UE
Travaux 3GPP et résultats
Dans l’étude de la Release 18, le groupe 3GPP RAN1 a démontré:
- Une précision au niveau sous-métrique du positionnement IA/ML dans des conditions NLOS extrêmes
- Une amélioration significative par rapport aux approches de positionnement classiques (plus de 10 mètres d’erreur)
Deux cas d’utilisation ont été identifiés:
- Positionnement IA/ML direct: le modèle produit les coordonnées de localisation de l’UE
- Positionnement assisté par IA/ML: le modèle produit une information de mesure de positionnement intermédiaire
Des évaluations approfondies ont été menées pour comprendre:
- La généralisation et la sensibilité des modèles
- L’impact des erreurs de synchronisation
- Les variations temporelles du canal
- Les déploiements avec différents encombrements
Pour le déploiement réseau, cinq cas ont été identifiés selon:
- Le type de sortie du modèle
- L’endroit où s’exécute le modèle (UE, LMF, station de base)
Dans la Release 19, 3GPP RAN1, a spécifié le support pour le positionnement IA/ML, priorisant certains cas et se concentrant sur l’identification de mesures améliorées pour l’entrée du modèle et la sortie du modèle.
Conclusion
L’IA transforme la couche physique des réseaux cellulaires en apportant des améliorations significatives dans:
- Le retour d’information sur l’état du canal, permettant une compression plus efficace et une meilleure reconstruction
- La gestion de faisceau, optimisant la sélection de faisceau et réduisant la surcharge de signalisation
- Le positionnement, atteignant une précision sous-métrique même dans des conditions défavorables
La progression vers des réseaux « IA-natifs » où l’intelligence artificielle est intégrée dès la conception promet d’améliorer considérablement les performances, la fiabilité et l’efficacité des systèmes de communication sans fil.
Références
[1] 5G America : Artificial Intelligence in Cellular Networks – Dec 2024 https://www.5gamericas.org/wp-content/uploads/2024/12/AI-Cell-Networks-Id-.pdf
[2] Ericcson : Defining AI native: A key enabler for advanced intelligent telecom network, https://www.ericsson.com/en/reports-and-papers/white-papers/ai-native