
Résumé
Le projet U-DESERVE 5G (Unified Direct-to-device Satellite Radio Enhanced Virtual Environment) a été lancé par le CNES dans le cadre du programme France 2030. Piloté par Thales Alenia Space en consortium avec Capgemini et Thales, ce projet vise à démontrer la faisabilité des communications directes entre satellites en orbite basse et terminaux mobiles ou fixes selon le standard 5G Release 17 du 3GPP.
La latence radio sera donc de 26 ms soit 52 ms RTT car la R17 propose l’architecture Transparent Payload. Le satellite LEO est donc un relai RF et cette approche se différencie de l’architecture présentée dans l’article précédent.
Introduction
Le CNES a sélectionné Thales Alenia Space, en partenariat avec Capgemini et Thales, dans le cadre d’un appel à projets lancé pour le compte de l’État au titre du programme France 2030, afin de mettre en œuvre une démonstration innovante de service de télécommunications par satellite selon le standard 5G.
Le projet dénommé U-DESERVE 5G a pour objectif de démontrer la faisabilité des communications directes entre satellites et terminaux mobiles ou fixes (5G Direct to Device ou D2D). Dans cette optique, un satellite de démonstration en orbite basse sera déployé afin de tester l’interopérabilité entre les réseaux 5G terrestres et non-terrestres.
Contexte et enjeux
Dans un contexte où la connectivité en tout temps et en tous lieux est devenue une priorité stratégique, à la fois pour répondre aux attentes du marché et garantir la résilience des infrastructures face aux crises, les technologies satellitaires apparaissent comme une solution complémentaire et essentielle aux réseaux terrestres.
Architecture technique du démonstrateur
Charge utile satellitaire
Au cœur du projet, une charge utile 5G innovante dotée d’antennes actives sera embarquée sur le satellite. Elle permettra de passer des appels et d’échanger des données directement entre le terminal mobile de test et le satellite, et ce sans passer par une station sol.
Composants du système
Le démonstrateur comprendra l’ensemble des éléments de la chaîne :
- Satellite de test
- Charge utile
- Segment sol NTN (Non-Terrestrial Network)
- Terminaux mobiles de tests
Le segment sol NTN désigne l’ensemble des infrastructures terrestres qui permettent de communiquer avec les réseaux non terrestres, comme les satellites, les drones à haute altitude (HAPS), ou les ballons stratosphériques.
Conformité aux standards
Le démonstrateur sera compatible avec la Release 17 du standard 5G 3GPP et fournira une plateforme d’essai de bout en bout, destinée à évaluer les performances du système 5G NTN/TN et à expérimenter des cas d’usages, notamment autour de l’Internet des objets (IoT).
Le consortium
Fort de son expertise dans le domaine des télécommunications et des actions menées avec succès en faveur de la normalisation de la 5G par satellite, Thales Alenia Space dirigera le consortium rassemblant :
Capgemini : En charge des solutions d’accès radio et des cœurs de réseau 4G/5G.
Thales : Étudiera la faisabilité d’un terminal 5G D2D à antenne directive fonctionnant dans la future bande C.
Orange : L’expertise d’opérateur est mise à profit et accueillera la démonstration sur son site de Bercenay.
SES : Pour l’étude de la mise en œuvre des services D2D.
Qualcomm : Fournira un terminal de test mobile compatible 5G NTN.
Loft Orbital : Responsable de la plateforme, de l’AIT (Assemblage, Intégration et Test), de la réservation de lancement et de l’exploitation du satellite pendant la phase de démonstration.
Objectifs du projet
Couverture étendue
Selon Stéphane Anjuère, 5G Venture Leader de Thales Alenia Space : « Ce nouveau projet relatif à la 5G directe par satellite ouvre à Thales Alenia Space la voie à une couverture haut débit étendue aux zones non desservies par les réseaux terrestres, mais aussi à des services de secours ou bien de continuité en cas de crise. »
Il ajoute : « En capitalisant sur son expertise dans les domaines des télécommunications géostationnaires et des constellations en orbites moyenne et basse, Thales Alenia Space a joué un rôle déterminant dans la normalisation de la 5G par satellite et a de ce fait toutes les cartes en main pour accompagner des futurs projets de grande envergure liés à la 5G « Direct to Device » par satellite. »
Innovation technologique
Alexandre Bottero, VP Réseaux et Systèmes d’infrastructure de Thales, a déclaré : « Ce projet pionnier de 5G par satellite représente une avancée majeure pour Thales et l’industrie des télécommunications. En développant des solutions modem 5G NTN D2D permettant une connectivité haut-débit, même dans les zones les plus isolées, nous posons les fondations pour l’avenir des communications mondiales et renforçons notre engagement pour un monde plus connecté et résilient. »
Engagement de Capgemini
Angélique Lallouet, Directrice Exécutive de Capgemini Engineering en France, a souligné : « Ce projet illustre parfaitement l’engagement de Capgemini à repousser les frontières de la connectivité. Grâce à notre expertise unique dans l’intégration des réseaux terrestres et non terrestres, ainsi qu’à notre maîtrise des solutions d’accès radio et des cœurs de réseau 4G/5G, Capgemini joue un rôle clé dans la démonstration de la 5G par satellite. Nous sommes particulièrement fiers de contribuer à cette initiative stratégique aux côtés de Thales Alenia Space, Thales et de l’ensemble des partenaires, et de collaborer à nouveau avec le CNES pour faire avancer la souveraineté technologique française et européenne. »
Applications visées
Le projet prévoit notamment de tester des scénarios de mobilité entre la couverture satellitaire et la couverture terrestre 5G, un enjeu clé dans la perspective d’une connectivité mondiale fluide et sans interruption.
Les cas d’usage expérimentés incluront l’Internet des objets (IoT).
Financement
Ce projet a été financé par le Gouvernement dans le cadre de France 2030, opéré conjointement pour le compte de l’État par le CNES et BpiFrance.
France 2030
France 2030, pensé en concertation avec les acteurs économiques, académiques, locaux et européens, offre à la France des moyens exceptionnels pour répondre aux défis écologiques, démographiques, économiques, industriels et sociaux d’un monde en mutation permanente.
Ce plan inédit d’innovation et d’industrie traduit une double ambition :
- D’une part, transformer durablement des secteurs clés de l’économie (énergie, automobile, aéronautique, numérique ou encore espace) par l’innovation et l’investissement industriel
- D’autre part positionner la France non pas seulement en acteur, mais bien en leader de l’économie de demain
Les acteurs du projet
Thales Alenia Space
Thales Alenia Space combine plus de quarante ans d’expérience et une diversité unique en termes d’expertise, de talents et de cultures. Les architectes de Thales Alenia Space conçoivent et délivrent des solutions innovantes pour les télécommunications, la navigation, l’observation de la Terre et la surveillance de l’environnement, l’exploration, les sciences et les infrastructures orbitales.
Société commune entre Thales (67%) et Leonardo (33%), Thales Alenia Space forme également la Space Alliance avec Telespazio pour proposer une offre complète de solutions incluant les services. Thales Alenia Space a réalisé un chiffre d’affaires de 2,23 milliards d’euros en 2024 et emploie plus de 8100 personnes dans 7 pays, avec 14 sites en Europe.
Thales
Thales est un leader mondial des hautes technologies pour les secteurs de la Défense, de l’Aérospatial et de la Cybersécurité & Digital. Son portefeuille de produits et de services innovants contribue à répondre à plusieurs défis majeurs : souveraineté, sécurité, durabilité et inclusion.
Le Groupe investit plus de 4 milliards d’euros par an en Recherche & Développement dans des domaines clés, en particulier pour les environnements critiques, tels que l’Intelligence Artificielle, la cybersécurité, le quantique et les technologies du cloud. Thales compte plus de 83 000 collaborateurs dans 68 pays. En 2024, le Groupe a réalisé un chiffre d’affaires de 20,6 milliards d’euros.
Capgemini
Capgemini, partenaire de la transformation business et technologique de ses clients, les accompagne dans leur transition vers un monde plus digital et durable, tout en créant un impact positif pour la société. Le Groupe, responsable et multiculturel, rassemble 350 000 collaborateurs dans plus de 50 pays.
Depuis plus de 55 ans, ses clients lui font confiance pour répondre à l’ensemble de leurs besoins grâce à la technologie. Capgemini propose des services et solutions de bout en bout, allant de la stratégie et du design jusqu’à l’ingénierie, en tirant parti de ses compétences de pointe en intelligence artificielle et IA générative, en cloud, et en data, ainsi que de son expertise sectorielle et de son écosystème de partenaires. Le Groupe a réalisé un chiffre d’affaires de 22,1 milliards d’euros en 2024.
Liens avec les travaux de recherche sur la 5G NTN
Le projet U-DESERVE 5G s’inscrit dans un contexte de recherche active sur les réseaux 5G non-terrestres (NTN). Plusieurs aspects techniques font l’objet de travaux approfondis dans la communauté académique et industrielle :
La gestion des cellules en environnement satellitaire
Un des défis majeurs des réseaux NTN concerne la gestion des cellules (ou faisceaux) projetées au sol par les satellites. Contrairement aux réseaux terrestres où les antennes sont fixes, les satellites en orbite basse se déplacent à plus de 27 000 km/h. La Release 17 du 3GPP a introduit le concept de Tracking Area Identifier (TAI) géofixe, où le TAC est associé à une zone géographique fixe au sol plutôt qu’au satellite mobile.
L’architecture du cœur de réseau 5G
L’architecture du cœur de réseau 5G repose sur une Service-Based Architecture (SBA) qui facilite l’intégration des réseaux non-terrestres. Les fonctions essentielles comme l’AMF (Access and Mobility Management Function), le SMF (Session Management Function) et l’UPF (User Plane Function) peuvent être déployées de manière distribuée.
Le NRF (Network Repository Function) fournit un contrôle des fonctions virtuelles et des services proposés. Le NSSF (Network Slice Selection Function) sélectionne le jeu de tranches réseau que l’utilisateur va pouvoir utiliser.
Les états du terminal en 5G
La spécification Release 15 relative à la 5G a introduit un état supplémentaire RRC_INACTIVE en plus des états RRC_CONNECTED et RRC_IDLE. Cet état a été introduit pour les terminaux IoT dans le but de réduire le nombre de requêtes de signalisation et par conséquent la consommation énergétique.
L’interface radioélectrique 5G-NR
L’interface radioélectrique 5G-NR utilise la modulation OFDM (Orthogonal Frequency Division Multiplexing). Une station de base 5G peut moduler au plus 3300 sous-porteuses. L’espacement entre sous-porteuses SCS (SubCarrier Spacing) est défini par la formulation : SCS=2^µ*15 kHz, avec µ la numérologie.
Le bloc de ressource RB (Resource Block) correspond à une allocation de N=12 sous-porteuses contiguës. Un slot est composé de 14 symboles OFDM consécutifs (trame normale).
Le Network Slicing
Le découpage réseau (network slicing) est l’une des caractéristiques différenciatrices majeures de la 5G afin de supporter une multitude de cas d’usage avec des exigences très différentes. Dans la spécification Release 17, une fonction spécifique a été ajoutée pour gérer les ressources des slices : le Network Slice Admission Control Function (NSACF).
Conclusion
Le projet U-DESERVE 5G représente une initiative majeure pour la démonstration de la 5G directe par satellite en France. Soutenu par le programme France 2030 et piloté par un consortium d’industriels de premier plan, ce projet vise à valider la faisabilité technique des communications 5G Direct to Device conformes aux standards 3GPP Release 17.
Cette démonstration s’inscrit dans la stratégie France 2030 qui vise à renforcer la position de la France dans les secteurs technologiques et industriels clés, dont l’aéronautique et l’espace. Elle contribue également à faire avancer la souveraineté technologique française et européenne dans le domaine des télécommunications spatiales.
Références
Sources officielles :
- Communiqué de presse Thales Alenia Space : « Thales Alenia Space pilote la démonstration 5G directe par satellite pour le CNES » (septembre 2025)
- Petites Affiches des Alpes Maritimes : « U DESERVE 5G : Thales Alenia Space pilote une démonstration de 5G directe par satellite pour le CNES » (9 septembre 2025
Standards 3GPP :
- Release 17 : Première spécification complète pour les communications 5G par satellite
- TS 23.501 : System Architecture for the 5G System
- 3GPP (3rd Generation Partnership Project) : Organisme de normalisation
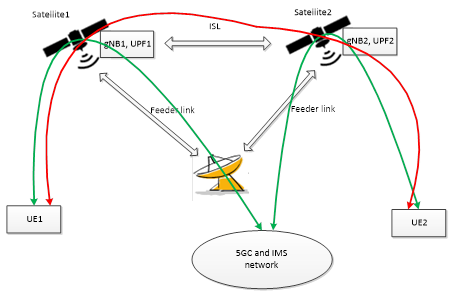
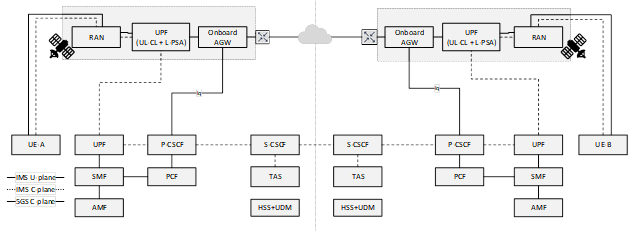
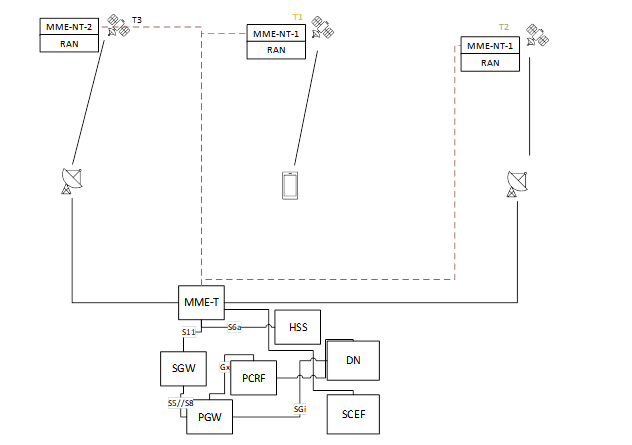 Figure 1 : Découpage du MME (extrait : TR 23.700-29h 06/2024)
Figure 1 : Découpage du MME (extrait : TR 23.700-29h 06/2024)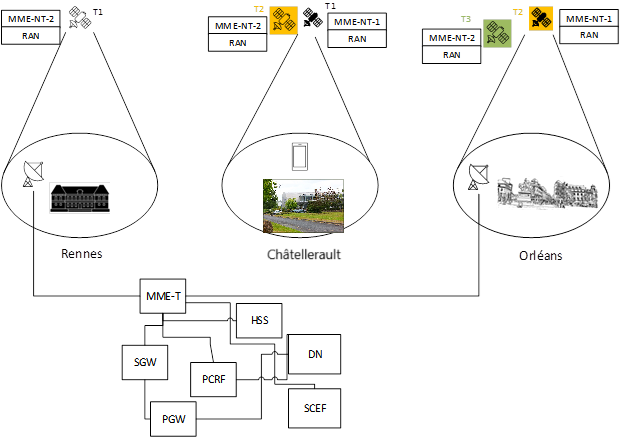 FIgure 2 : Couverture du satellite
FIgure 2 : Couverture du satellite Figure 1 : Procédure de déconnexion N2/S1
Figure 1 : Procédure de déconnexion N2/S1