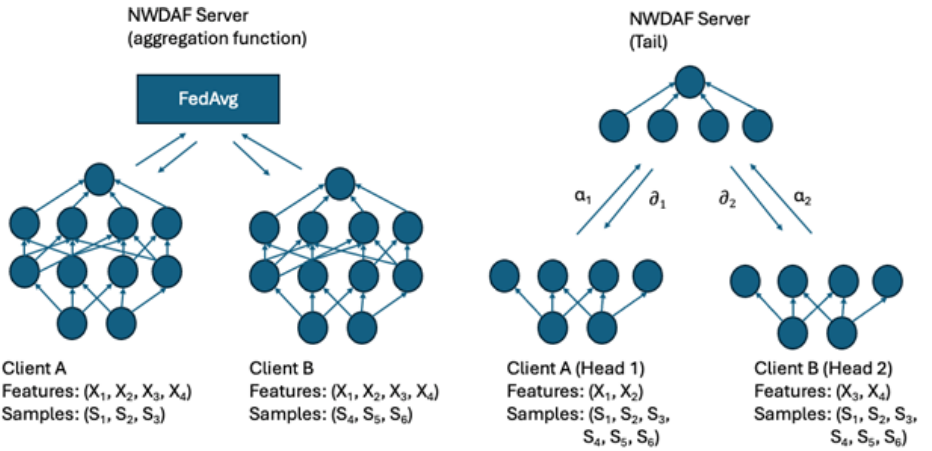
AI appliquée à la couche liaison de données (Link Layer L2) et réseau (Network Layer L3): Une analyse approfondie
Introduction
Ces couches jouent un rôle crucial dans le fonctionnement des réseaux cellulaires modernes. La couche de liaison de données (L2) gère l’allocation des ressources, la fiabilité du transfert de données entre deux dispositifs sur un lien physique, comprenant des fonctions comme la détection d’erreurs, la correction d’erreurs et le contrôle du trafic. La couche réseau (L3) est responsable du routage des paquets à travers le réseau et de la gestion de la mobilité, faisant d’elle un élément essentiel pour maintenir une connectivité transparente lorsque les utilisateurs se déplacent.
Cette analyse approfondie explorera comment l’IA transforme ces couches, en examinant les défis existants, les solutions proposées, et l’impact potentiel sur les performances globales du réseau et l’expérience utilisateur.
Distinction entre l’IA à la couche physique et aux couches supérieures
Différence de portée
L’IA à la couche physique (L1) opère dans un cadre plus localisé, se concentrant sur l’amélioration de l’efficacité de la transmission et de la réception des signaux au niveau du dispositif et de la cellule. Son champ d’action est relativement restreint, bien que fondamental pour la performance du réseau.
En revanche, l’IA dans les couches L2 et L3 opère dans un cadre plus large, influençant les politiques et stratégies à l’échelle du réseau qui affectent de multiples dispositifs, cellules, et potentiellement l’ensemble du réseau. Cette différence de portée est essentielle pour comprendre l’impact potentiel de l’IA à ces niveaux.
Différence d’impact
L’impact de l’IA à la couche physique est souvent immédiat, améliorant en temps réel la qualité de la communication. Les algorithmes d’IA à ce niveau contribuent directement à optimiser des paramètres comme la modulation, le codage, ou la formation de faisceaux, avec des effets quasi instantanés sur la qualité du signal.
Par contre, l’IA dans les couches L2 et L3 a un impact plus stratégique et à plus long terme. Elle façonne la manière dont le réseau répond aux conditions changeantes, gère les ressources sur la durée, et assure la performance et la fiabilité du réseau à long terme. Ces décisions peuvent avoir des effets durables sur la santé du réseau et la qualité de service fournie aux utilisateurs.
L’IA dans la couche de liaison de données (L2)
La couche de liaison de données (L2) est responsable de la gestion des ressources, de la fiabilité du transfert de données entre deux dispositifs sur un lien physique, et englobe des fonctions comme la détection d’erreurs, la correction d’erreurs et le contrôle du trafic. L’intégration de l’IA à ce niveau transforme fondamentalement ces processus.
Allocation dynamique des ressources
L’un des apports majeurs de l’IA à la couche L2 concerne l’allocation dynamique des ressources:
Prédiction des modèles de trafic
Les algorithmes d’IA peuvent analyser les historiques de trafic et le comportement des utilisateurs pour prévoir les futures demandes en bande passante. Cette capacité prédictive permet au réseau d’anticiper les congestions potentielles et d’allouer proactivement les ressources nécessaires.
Par exemple, un modèle d’IA peut apprendre que certaines zones géographiques connaissent des pics de trafic à des moments spécifiques de la journée ou lors d’événements particuliers. En utilisant ces informations, le réseau peut réserver la bande passante appropriée et ajuster les paramètres d’ordonnancement avant même que la demande n’augmente.
Ordonnancement intelligent
L’IA permet un ordonnancement (scheduling) plus sophistiqué des ressources entre différents dispositifs en fonction de multiples facteurs contextuels:
- Les conditions du canal pour chaque dispositif
- La priorité et la sensibilité à la latence de chaque type de trafic
- Les accords de niveau de service (SLA) pour différents clients
- L’état de la batterie des dispositifs mobiles
- Les modèles d’utilisation historiques
Cet ordonnancement intelligent garantit que les ressources limitées sont allouées de manière à optimiser l’expérience utilisateur globale tout en respectant diverses contraintes opérationnelles.
Gestion proactive de la congestion
Les techniques d’IA peuvent identifier les signes avant-coureurs de congestion réseau et prendre des mesures préventives pour l’éviter:
- Redirection du trafic vers des chemins alternatifs
- Modification temporaire des priorités de certains flux de données
- Ajustement adaptatif des algorithmes de contrôle de flux
- Allocation préemptive de ressources supplémentaires dans les zones à risque
Cette approche proactive de la gestion de la congestion permet d’éviter les dégradations de service qui surviendraient avec des méthodes réactives traditionnelles.
Prédiction et correction d’erreurs
Un autre domaine où l’IA apporte une valeur significative à la couche L2 est la prédiction et la correction d’erreurs:
Anticipation des erreurs de transmission
Les modèles d’IA peuvent anticiper les erreurs potentielles dans la transmission de données en analysant:
- Les modèles de bruit et d’interférence dans différents environnements
- Les caractéristiques de propagation du signal à différentes fréquences
- L’historique des performances de transmission dans des conditions similaires
- Les défaillances récurrentes ou systémiques dans certaines parties du réseau
Cette capacité d’anticipation permet au système de prendre des mesures préventives avant que les erreurs ne se produisent, réduisant ainsi le besoin de retransmissions.
Mécanismes de correction préemptifs
Au lieu de simplement réagir aux erreurs détectées, l’IA permet la mise en œuvre de mécanismes de correction préemptifs:
- Ajustement dynamique des schémas de codage correcteurs d’erreurs
- Adaptation du niveau de redondance en fonction des conditions prévues du canal
- Mise en œuvre de techniques de diversité spécifiques au contexte
- Priorisation stratégique des paquets ayant une plus forte probabilité de transmission réussie
Ces approches proactives réduisent considérablement le taux d’erreur global et améliorent l’efficacité des ressources réseau en minimisant les retransmissions.
Gestion adaptative de la qualité de service (QoS)
La gestion de la qualité de service à la couche L2 bénéficie considérablement de l’intégration de l’IA:
Prédiction des conditions réseau
L’IA permet de prévoir l’évolution des conditions du réseau à court et moyen terme, ce qui est crucial pour maintenir la QoS:
- Prédiction des fluctuations de charge sur différentes cellules
- Anticipation des interférences basée sur l’utilisation historique du spectre
- Prévision des effets des conditions météorologiques sur les performances du réseau
- Modélisation de l’impact des grands événements sur la demande de ressources
Ces prédictions permettent une gestion proactive des ressources pour maintenir la QoS même dans des conditions changeantes.
Priorisation contextuelle du trafic
L’IA permet une priorisation plus nuancée et contextuelle du trafic par rapport aux approches basées sur des règles statiques:
- Les applications à faible latence (comme le gaming en ligne ou la réalité virtuelle) peuvent recevoir une priorité plus élevée lorsque les utilisateurs sont activement engagés.
- Les applications critiques (comme la télémédecine ou les communications d’urgence) peuvent être identifiées et priorisées dynamiquement.
- Les flux de données susceptibles de contribuer significativement à l’expérience utilisateur peuvent être favorisés en fonction du contexte d’utilisation.
Cette priorisation intelligente garantit que les ressources limitées sont allouées de manière à maximiser la valeur perçue par les utilisateurs.
Équilibrage dynamique des exigences contradictoires
L’IA excelle dans l’équilibrage de multiples objectifs contradictoires, ce qui est particulièrement utile pour la gestion de la QoS:
- Équilibrer la latence et le débit pour différents types d’applications
- Concilier l’équité entre les utilisateurs et l’optimisation des performances globales
- Trouver le compromis optimal entre l’efficacité énergétique et la performance
- Pondérer les besoins des applications en temps réel par rapport au trafic en arrière-plan
Cet équilibrage dynamique permet d’offrir la meilleure expérience possible à tous les utilisateurs malgré des ressources limitées et des demandes variées.
L’IA dans la couche réseau (L3)
La couche réseau (L3) est responsable du routage des paquets à travers le réseau et de la gestion de la mobilité, faisant d’elle un élément essentiel pour maintenir une connectivité transparente lorsque les utilisateurs se déplacent entre différentes cellules du réseau.
Gestion intelligente de la mobilité
L’un des apports majeurs de l’IA à la couche L3 concerne la gestion de la mobilité:
Prédiction des modèles de mobilité
Les algorithmes d’IA peuvent analyser les historiques de déplacement des utilisateurs et prédire leurs mouvements futurs avec une précision remarquable:
- Identification des trajets réguliers (domicile-travail, par exemple)
- Reconnaissance des modèles de déplacement spécifiques à certaines heures ou jours
- Prédiction des zones de congestion en fonction des événements programmés
- Anticipation des changements de vitesse de déplacement basée sur les infrastructures de transport
Ces prédictions permettent au réseau d’anticiper les besoins de handover plutôt que d’y réagir.
Optimisation proactive des handovers
Sur la base des prédictions de mobilité, l’IA peut optimiser le processus de handover de plusieurs façons:
- Préparation anticipée des ressources dans les cellules cibles probables
- Détermination du moment optimal pour initier le handover, minimisant les risques de déconnexion
- Sélection intelligente de la cellule cible optimale parmi plusieurs candidates
- Adaptation des paramètres de handover en fonction du profil de mobilité spécifique de chaque utilisateur
Cette approche proactive réduit considérablement les risques de déconnexions, les handovers inutiles, et les effets « ping-pong » où un utilisateur est transféré de manière répétée entre deux cellules.
Réduction des interruptions de service
L’IA contribue significativement à réduire les interruptions de service lors des transitions entre cellules:
- Coordination des handovers avec les moments de faible activité dans les sessions de l’utilisateur
- Mise en place préemptive de tunnels de données entre cellules source et cible
- Ajustement dynamique des priorités de trafic pendant les phases critiques du handover
- Optimisation des paramètres de reconnexion en fonction du type de service utilisé
Ces optimisations garantissent une expérience plus fluide aux utilisateurs, particulièrement pour les applications sensibles à la latence comme les appels vidéo ou les jeux en ligne.
Équilibrage de charge entre cellules
Un autre domaine clé où l’IA transforme la couche L3 est l’équilibrage de charge entre cellules:
Analyse en temps réel de la charge réseau
L’IA permet une analyse sophistiquée et en temps réel de la charge sur différentes cellules:
- Évaluation multidimensionnelle de la charge (nombre d’utilisateurs, demande de bande passante, profils de trafic)
- Détection des déséquilibres émergents avant qu’ils n’affectent la performance
- Identification des cellules sous-utilisées pouvant absorber du trafic supplémentaire
- Prévision de l’évolution de la charge à court terme pour guider les décisions d’équilibrage
Cette analyse en temps réel fournit une base solide pour des décisions d’équilibrage de charge optimales.
Distribution intelligente du trafic
Sur la base de cette analyse, l’IA peut orchestrer une distribution plus intelligente du trafic:
- Ajustement dynamique des paramètres de sélection de cellule pour influencer les décisions de connexion des nouveaux utilisateurs
- Modification contrôlée des seuils de handover pour encourager la migration d’utilisateurs vers des cellules moins chargées
- Adaptation des puissances d’émission pour modifier les zones de couverture effective des cellules
- Priorisation stratégique de certains utilisateurs pour le transfert vers d’autres cellules
Cette distribution intelligente permet de maximiser l’utilisation des ressources disponibles tout en maintenant une bonne qualité de service pour tous les utilisateurs.
Prévention proactive des congestions
L’IA excelle également dans la prévention proactive des congestions au niveau cellulaire:
- Identification précoce des tendances de trafic susceptibles de conduire à une congestion
- Déclenchement préemptif de mécanismes d’équilibrage avant l’apparition de problèmes de performance
- Coordination des équilibrages de charge avec d’autres optimisations réseau pour éviter les effets secondaires indésirables
- Ajustement progressif des paramètres pour éviter les changements brusques qui pourraient perturber les utilisateurs
Cette approche proactive permet d’éviter les dégradations de service qui surviendraient avec des méthodes réactives traditionnelles.
Économie d’énergie réseau
L’IA contribue de manière significative à l’optimisation de la consommation énergétique au niveau de la couche réseau:
Prédiction des périodes de faible trafic
Les algorithmes d’IA peuvent analyser les modèles historiques de trafic pour prédire avec précision les périodes de faible utilisation:
- Identification des cycles quotidiens, hebdomadaires et saisonniers dans l’utilisation du réseau
- Reconnaissance des modèles spécifiques liés aux événements locaux, jours fériés, ou conditions exceptionnelles
- Prévision des fluctuations à court terme dans la demande de trafic
- Détection des zones géographiques connaissant des périodes d’inactivité prolongées
Ces prédictions permettent une planification optimale des économies d’énergie sans compromettre la qualité du service.
Désactivation dynamique des ressources sous-utilisées
Sur la base de ces prédictions, l’IA peut orchestrer la désactivation intelligente des ressources réseau:
- Mise en veille sélective de certaines cellules pendant les heures creuses
- Réduction contrôlée de la bande passante disponible lorsque la demande est faible
- Désactivation temporaire de certaines bandes de fréquence ou composants RF
- Coordination des cycles de veille entre cellules voisines pour maintenir une couverture minimale
Cette désactivation dynamique permet de réaliser des économies d’énergie substantielles tout en maintenant la disponibilité du réseau.
Réactivation préemptive basée sur les prévisions
L’aspect le plus innovant de cette approche est la capacité à réactiver les ressources de manière préemptive:
- Anticipation des augmentations de trafic avant qu’elles ne se produisent
- Réactivation progressive des ressources pour éviter les pics de consommation
- Priorisation de la réactivation des cellules en fonction des prévisions de demande spécifiques à chaque zone
- Coordination de la réactivation avec d’autres optimisations réseau pour une transition fluide
Cette réactivation préemptive garantit que les utilisateurs ne subissent aucune dégradation de service malgré les économies d’énergie réalisées.
Le rôle du 3GPP dans la standardisation de l’IA/ML pour L2 et L3
Développements des Releases 17 et 18
Les efforts initiaux d’intégration de l’IA/ML dans le 3GPP ont commencé avec la Release 17, qui s’est concentrée sur l’amélioration des fonctions SON (Self-Organizing Networks) telles que:
- L’économie d’énergie du réseau, permettant une réduction significative de la consommation énergétique des stations de base sans compromettre l’expérience utilisateur
- L’équilibrage de charge, visant à distribuer efficacement le trafic entre les cellules pour éviter la congestion et optimiser l’utilisation des ressources
- L’optimisation de la mobilité, améliorant la gestion des handovers pour réduire les interruptions de service lors des déplacements des utilisateurs
Ces efforts se sont poursuivis et amplifiés dans la Release 18, avec un accent particulier sur:
- L’affinement des méthodes d’entraînement des modèles d’IA
- L’amélioration des techniques de déploiement dans le réseau
- L’élaboration de standards pour assurer l’interopérabilité des solutions basées sur l’IA entre différents fournisseurs
- La définition de métriques communes pour évaluer les performances des systèmes basés sur l’IA
Cas d’utilisation pratiques
Le 3GPP a identifié plusieurs cas d’utilisation pratiques pour l’IA/ML dans les couches L2 et L3, notamment:
- Économie d’énergie du réseau: L’IA/ML est utilisée pour prédire les périodes de faible trafic et optimiser l’activation/désactivation des composants du réseau, permettant des économies d’énergie substantielles tout en maintenant la qualité de service.
- Équilibrage de charge: Les algorithmes d’IA analysent les modèles de trafic, l’utilisation des ressources et les conditions du réseau pour répartir intelligemment les utilisateurs entre les cellules, évitant ainsi les congestions localisées.
- Optimisation de la mobilité: L’IA/ML améliore la gestion des handovers en prédisant les mouvements des utilisateurs et en adaptant dynamiquement les paramètres de handover en fonction des conditions spécifiques, réduisant ainsi les interruptions de service lors des déplacements.
Ces cas d’utilisation démontrent la valeur pratique de l’IA/ML dans les couches L2 et L3 et fournissent un cadre pour le développement de solutions standardisées.
Synergies entre l’IA dans les différentes couches du réseau
Coordination entre les couches physique et liaison de données
L’IA appliquée à la couche physique (L1) et à la couche de liaison de données (L2) peut fonctionner de manière coordonnée pour maximiser les performances du réseau:
- Adaptation conjointe: Les algorithmes d’IA à la couche L1 peuvent optimiser les paramètres de transmission (modulation, codage, formation de faisceaux) en fonction des décisions d’allocation de ressources prises au niveau L2, et vice versa.
- Partage d’informations contextuelles: Les insights générés par l’IA à une couche peuvent enrichir les modèles utilisés à l’autre couche, permettant des décisions plus informées et cohérentes.
- Optimisation multi-objectifs: Les objectifs d’optimisation peuvent être coordonnés entre les couches pour éviter les optimisations locales qui pourraient être globalement sous-optimales.
- Adaptation aux conditions dynamiques: L’IA peut faciliter l’adaptation rapide des deux couches aux conditions changeantes du réseau, maintenant des performances optimales dans des environnements complexes et dynamiques.
Intégration avec la gestion de réseau de bout en bout
L’IA dans les couches L2 et L3 s’intègre également avec les systèmes de gestion de réseau de bout en bout:
- Alignement avec les objectifs commerciaux: Les optimisations au niveau L2/L3 peuvent être guidées par des objectifs commerciaux et des KPIs définis au niveau de la gestion du réseau.
- Orchestration globale: Les capacités d’IA au niveau L2/L3 peuvent être orchestrées dans le cadre d’une stratégie d’optimisation plus large qui englobe tous les aspects du réseau.
- Feedback bidirectionnel: Les informations circulent dans les deux sens, avec les systèmes de gestion de réseau fournissant du contexte aux modèles d’IA L2/L3, et ces derniers remontant des insights détaillés pour informer les décisions stratégiques.
- Évolution coordonnée: Les capacités d’IA à tous les niveaux peuvent évoluer de manière coordonnée, assurant que les améliorations sont cohérentes et complémentaires.
Interaction avec les couches applicatives
L’IA dans les couches L2 et L3 interagit également avec les couches applicatives supérieures:
- Optimisations spécifiques aux applications: Les modèles d’IA peuvent adapter les paramètres L2/L3 en fonction des besoins spécifiques des applications en cours d’exécution.
- Feedback de qualité d’expérience: Les informations sur la qualité d’expérience perçue au niveau applicatif peuvent être utilisées pour guider les optimisations L2/L3.
- Prédiction des besoins applicatifs: L’IA peut anticiper les besoins des applications avant même qu’ils ne soient explicitement communiqués, permettant une allocation proactive des ressources.
- Adaptation conjointe: Dans certains cas, les applications et les couches réseau peuvent s’adapter mutuellement de manière coordonnée pour optimiser l’expérience utilisateur globale.
Impact sur les performances du réseau et l’expérience utilisateur
L’intégration de l’IA dans les couches L2 et L3 a un impact significatif sur les performances globales du réseau et l’expérience utilisateur.
Amélioration de l’efficacité des ressources
L’IA permet une utilisation nettement plus efficace des ressources réseau limitées:
- Allocation optimisée: Les ressources sont allouées avec une précision inégalée, en tenant compte de multiples facteurs contextuels pour maximiser l’utilité globale.
- Réduction du gaspillage: L’IA minimise le gaspillage de ressources en adaptant finement l’allocation aux besoins réels plutôt qu’à des estimations grossières.
- Anticipation des besoins: La capacité à prédire les besoins futurs permet une planification plus efficace de l’utilisation des ressources sur différentes échelles de temps.
- Équilibrage dynamique: Les ressources peuvent être réallouées dynamiquement en fonction de l’évolution des conditions du réseau et des priorités.
Ces améliorations d’efficacité se traduisent par une capacité accrue du réseau à servir plus d’utilisateurs avec une meilleure qualité de service, sans nécessiter d’investissements proportionnels dans l’infrastructure.
Réduction de la latence et des interruptions
L’IA dans les couches L2 et L3 contribue significativement à réduire la latence et les interruptions:
- Handovers optimisés: La prédiction des mouvements des utilisateurs permet des handovers plus fluides et moins susceptibles de causer des interruptions.
- Prévention des congestions: L’anticipation et la prévention proactive des congestions réseau réduisent les pics de latence qui affectent négativement l’expérience utilisateur.
- Routage intelligent: L’IA peut identifier les chemins optimaux à travers le réseau pour minimiser la latence pour les applications sensibles au temps.
- Allocation prioritaire: Les ressources peuvent être allouées prioritairement aux flux de données sensibles à la latence, garantissant une performance constante même en cas de charge réseau élevée.
Ces réductions de latence et d’interruptions sont particulièrement critiques pour les applications émergentes comme la réalité augmentée/virtuelle, les véhicules autonomes, et la télémédecine, qui dépendent d’une connectivité fiable et à faible latence.
Adaptation aux besoins diversifiés des utilisateurs
L’un des avantages majeurs de l’IA dans les couches L2 et L3 est sa capacité à adapter le comportement du réseau aux besoins diversifiés des utilisateurs:
- Personnalisation implicite: Le réseau peut s’adapter aux modèles d’utilisation spécifiques de chaque utilisateur sans configuration explicite.
- Différenciation contextuelle: Les ressources peuvent être allouées différemment en fonction du contexte d’utilisation (professionnel vs. loisir, critique vs. non-critique, etc.).
- Support des cas d’usage émergents: L’IA facilite l’adaptation du réseau à de nouveaux cas d’usage aux exigences inédites, sans nécessiter une refonte complète des systèmes.
- Équilibre entre équité et optimisation: L’IA peut trouver des équilibres sophistiqués entre l’équité dans l’allocation des ressources et l’optimisation des performances globales.
Cette adaptabilité accrue permet aux opérateurs de proposer une expérience plus personnalisée et satisfaisante à leurs utilisateurs, renforçant ainsi la valeur perçue de leurs services.
Amélioration de la fiabilité et de la résilience
L’IA dans les couches L2 et L3 contribue également à améliorer la fiabilité et la résilience du réseau:
- Détection précoce des anomalies: Les modèles d’IA peuvent identifier des schémas subtils indiquant des problèmes émergents avant qu’ils n’affectent visiblement les performances.
- Adaptation proactive: Le réseau peut s’adapter proactivement aux changements de conditions ou aux défaillances partielles, maintenant la continuité du service.
- Récupération intelligente: En cas de défaillance, l’IA peut orchestrer des processus de récupération optimisés qui minimisent l’impact sur les utilisateurs et restaurent rapidement les services normaux.
- Apprentissage continu: Les systèmes d’IA peuvent apprendre continuellement des incidents passés pour améliorer leur réponse aux événements futurs similaires.
Cette amélioration de la fiabilité et de la résilience est particulièrement importante à mesure que les réseaux cellulaires deviennent une infrastructure critique supportant des services essentiels dans de nombreux secteurs.
Défis et considérations pour l’implémentation
Malgré ses nombreux avantages, l’intégration de l’IA dans les couches L2 et L3 présente plusieurs défis et considérations importantes.
Complexité des modèles et exigences de calcul
L’implémentation de modèles d’IA sophistiqués dans les couches L2 et L3 soulève des préoccupations concernant la complexité et les ressources de calcul:
- Équilibre performance-complexité: Il est nécessaire de trouver un équilibre entre la sophistication des modèles d’IA et leur viabilité pratique dans des environnements aux ressources limitées.
- Exigences en temps réel: De nombreuses décisions au niveau L2/L3 doivent être prises en temps réel, imposant des contraintes strictes sur la latence d’inférence des modèles d’IA.
- Efficacité énergétique: L’exécution de modèles d’IA complexes consomme de l’énergie, ce qui peut contre

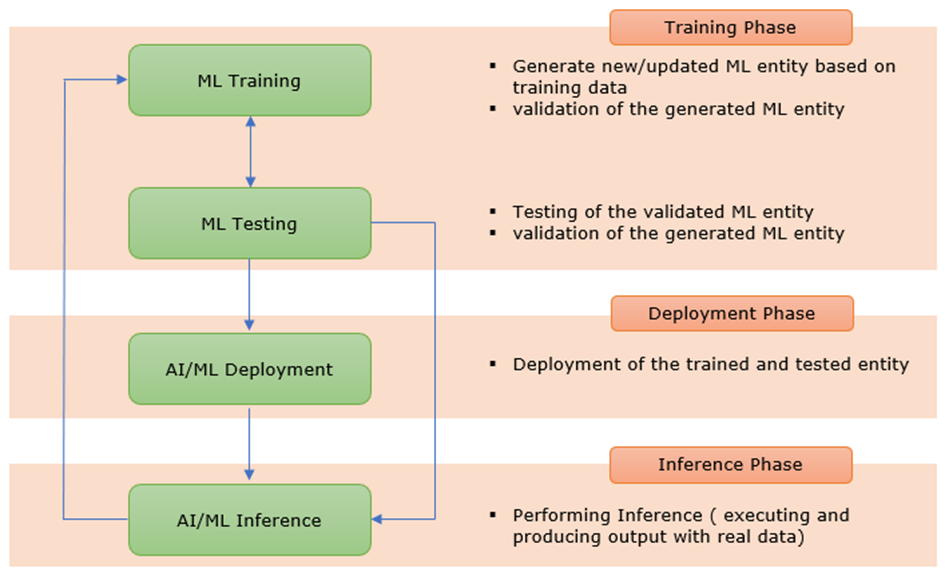 Figure 1 : extraite de Sharetechnote https://www.sharetechnote.com/html/5G/5G_AI_ML.html
Figure 1 : extraite de Sharetechnote https://www.sharetechnote.com/html/5G/5G_AI_ML.html